[CMSC 313 Home] |
[Syllabus] |
[Homework] |
[Projects] |
[Lecture Notes] |
[Printable all notes] |
[Files] |
[NASM resource] |
CMSC 313 Projects
Project 1
Project 2
Project 3
Project 4
Project 5
Submitting your Project
The project is to be submitted on linux.gl.umbc.edu as
submit cs313_squire proj1 convert.asm
submit cs313_squire proj2 math_64.asm
submit cs313_squire proj3 plotc.asm
submit cs313_squire proj4 proj4.vhdl or
submit cs313_squire proj4 proj4.v
submit cs313_squire proj5 proj5.vhdl or
submit cs313_squire proj5 proj5.v
To see what is submitted
submitls cs313_squire proj1
To delete a file that was submitted
submitrm cs313_squire proj1 convert.asm
Getting Started
Using UMBC computer
From anywhere you can reach the internet:
ssh your-username@linux.gl.umbc.edu # or use putty, etc.
your-password
mkdir cs313 # or whatever directory name you want, only once
cd cs313 # every time you log in for CMSC 313
# Get some sample files. (some not needed until later)
cp /afs/umbc.edu/users/s/q/squire/pub/download/hello_64.asm .
cp /afs/umbc.edu/users/s/q/squire/pub/download/intarith_64.asm .
cp /afs/umbc.edu/users/s/q/squire/pub/download/fltarith_64.asm .
cp /afs/umbc.edu/users/s/q/squire/pub/download/xor.circ .
# be sure to type the final space dot
# you can type in the command lines or get these Makefile's
cp /afs/umbc.edu/users/s/q/squire/pub/download/Makefile_nasm Makefile
# test compile hello_64.asm
nasm -f elf64 hello_64.asm # or just make (you have Makefile)
gcc -m64 -o hello_64 hello_64.o
./hello_64 > hello_64.out
cat hello_64.out
ls -ltr # see files you have
Or type
make # or make -f Makefile_nasm if copied that way
ls -ltr
If this did not work, see Help Desk, T.A. or instructor
Write and submit a NASM assembly language program
"convert.asm" that implements the number conversions
like you did for Homework 1. The files
integer print and test ifint_64.asm
integer arithmetic intarith_64.asm
floating print and test ifflt_64.asm
floating srithmetic fltarith_64.asm
will be helpful.
You start with two constants in the .data section
dec1: db '1','2','6','.','3','7','5',0
bin1: dq 01010110110111B ; 10101101.10111 note where binary point should be
You convert dec1 to a string of characters that is
the binary representation of 126.3750 with a binary point
and three bits to the right of the binary point.
OK to just print integer bits on one line,
then fraction bits on next line.
Print your characters with printf.
Look up how to compute in nasm,
intarith.asm for converting dec1 '1','2','3'
fltarith.asm for converting dec1 '.','3','7','5','0'
Remember '1' is ASCII, also times 100
mov rax,0
mov al,[dec1] ; ASCII 1
sub rax,48 ; now have binary 1
imul qword [a100] ; now have binary 100 add 2*10+6 [dec1+1]*10+[dec1+2]
mov [sum], rax
mov rax,0
mov al,[dec1+1] ; ASCII 2
sub rax,48 ; now have binary 2
imul qword [a10]
add rax, [sum] ; now have binary 120
mov [sum], rax
When you get binary 126, in [sum] 1111110
now print the bits, do not need leading zeros.
Then do .375, ok to get integer 375, float it, 375.0 and
divide by float 1000.0 to get float 0.375 and use lecture 1.
You convert bin1 to a string of characters that is
the decimal representation of 10101101.10111.
Print your characters (string) with printf or a kernel call.
Use %ld to print 64 bit integers, or use %c to print characters.
mov rax, [bin1]
shr rax, 5 ; shift off .10111 5 bits '.' not stored
mov [whole], rax ; save 10101101 can print with %ld
mov rax, [bin1]
and rax, 31 ; 31 in binary is 11111 save the 10111 fraction
mov [frack], rax
mov rax, [whole]
and rax, 1 ; save only bottom bit
mov [bit1], rax ; or [bit] using resb 7
mov rax, [whole]
shr rax, 1
and rax, 1 ; save only second bit
mov [bit2], rax ; or [bit+1] using resb 7
mov rax, [whole]
shr rax, 2
and rax, 1 ; save only third bit
mov [bit3], rax ; or [bit+2] using resb 7
print bits each a %ld
then do fraction top bit is 0.5, next bit is 0.25,
next bit is 0.124 1/2 1/4 1/8 etc.
You may use any method of your choice, and you may print results
as four numbers: '1','2','6' as 1's and 0's, binary.
'.','3','7','5' as '.' 1's and 0's binary.
010101101 as a decimal number, integer
.10111 as a decimal number, .dddd decimal fraction.
submit your file, when it is working correctly,
submit cs313_squire proj1 convert.asm
Your file must assemble with no errors and execute
with the commands:
nasm -f elf64 convert.asm
gcc -m64 -o convert convert.o
./convert # ./ needed if '.' not first in PATH
Then submit cs313_squire proj1 convert.asm
Note: '1' is an ASCII character. Subtract 48 from an ASCII
character to get a binary number. Add 48 to a binary
number in the range 0 to 9 to get the ASCII character
'0' to '9'.
'1','2','6' is 1*100 + 2*10 + 6 = 126, binary in a register.
See horner_64.asm for sample loops.
and loopint_64.asm another sample.
You do not have to use loops, you can solve just specific problem.
It is OK to process and print one character or digit at a time.
A snippet of sample code for printing in Nasm:
dec1: db '1','2','6','.','3','7','5', 0
fmt_char: db "%c",0 ; no '\n' thus no 10
fmt_dig: db "%1ld",0 ; print just one digit, e.g. 0 or 1
fmt_end: db 10, 0 ; just end line
mov rdi,fmt_char ; print a single character
mov rax, 0 ; be safe, zero all rax
mov al, [dec1] ; byte into bottom of rax
mov rsi, rax ; must go 64-bit to 64-bit
mov rax, 0 ; no float
call printf
mov rdi,fmt_dig ; print a single character as digit
mov rax, 0 ; be safe, zero all rax
mov al, [dec1+1] ; next byte into bottom of rax
sub rax, 48 ; change character digit to number
; imul rax, 10 ; '2' is 20 need to add up 1*100+2*10+4
mov rsi, rax ; must go 64-bit to 64-bit
mov rax, 0 ; no float
call printf
mov rdi,fmt_end ; print end of line
mov rax, 0 ; no float
call printf
Note: and rax,1 ; print with %1ld, prints bottom bit as 0 or 1
; shr rax to get the bit you want
Hint, C code, for converting .375 to .011
frac_bin.c
frac_bin.out
Beware rounding when storing double as integer.
May need fld, fld, compp as in ifflt_64.asm
One possible way to print first two binary numbers:
dec1: db '1','2','6','.','3','7','5',0
fmt1: db "126 = %ld%ld%ld%ld",0 ; format for 126, first 4 bits
fmt2: db "%ld%ld%ld", 10, 0 ; format for last 3 bits
fmt3: db ".375 = %ld%ld%ld",10,0 ; format for .375
bitw: resq 7 ; reserve 7 64-bit word for bits 1 or 0
bitf: resq 3 ; reserve 3 words for bits 1 or 0
; compute bits for 126 into bitw top bit first
; compute bits for .375 into bitf top bit first
mov rdi, fmt1 ; first arg, format
mov rsi, [bitw] ; second arg
mov rdx, [bitw+1*8] ; third arg
mov rcx, [bitw+2*8] ; fourth arg
mov r8, [bitw+3*8] ; fifth arg
mov r9, [bitw+4*8] ; sixth arg
mov rax, 0 ; no xmm used
call printf ; Call C function
mov rdi, fmt2 ; first arg, format
mov rsi, [bitw+5*8] ; seventh arg
mov rdx, [bitw+6*8] ; eighth arg
mov rax, 0 ; no xmm used
call printf ; Call C function
mov rdi, fmt3 ; first arg, format
mov rsi, [bitf] ; second arg
mov rdx, [bitf+8] ; third arg
mov rcx, [bitf+2*8] ; forth arg
mov rax, 0 ; no xmm used
call printf ; Call C function
for bin1 use %ld for integer part, %f for fraction
Partial credit: 25% for decimal integer to binary
25% for decimal fraction to binary
25% for binary integer to decimal
25% for binary fraction to decimal
Zero points if your convert.asm does not compile,
if your convert.asm just prints the answers without
doing the conversion.
if two or more convert.asm are copied
Write and submit NASM assembly language functions
that implement the given "C" functions in math_64.c
The main program test_math_64.c
that does not know how the functions are implemented.
The test program is test_math_64.c
The .h file with function prototypes is math_64.h
Your correct output should be test_math_64.chk
Note: There is zero credit when math_64.asm does not compile without errors.
Your file must assemble with no errors and execute on linux.gl.umbc.edu
with the commands:
nasm -g -f elf64 math_64.asm
gcc -g3 -m64 -o test_math_64 test_math_64.c math_64.o
./test_math_64 > test_math_64.out
cat test_math_64.out
Then submit cs313_squire proj2 math_64.asm
OK to use printf for debug print to help in development.
Please comment out debug print before submit.
OK to have math_64.c as long comment in your math_64.asm
For debugging due to segfault:
gdb test_math_64
break main
run
step
step keep stepping until segfault, thus see where you have a bug
nexti use in place of step to step one instruction at a time
or, if it runs to segfault,
backtrace
disassemble will show you address of instructions
q you need q for quit, then y for yes to quit gdb
y
Your project is to convert math_64.c to math_64.asm
You may use pre_math_64.asm
renamed to math_64.asm as a start. Compile and run to be sure
compilation and execution are working, then add project code.
Using my pre_math_64.asm as your math_64.asm
in dot:
mov rcx, [n] ; number of items n..1, need -8 for n-1..0
mov rax, [x] ; address of x array need *8 for each i
mov rbx, [y] ; address of y array
dotloop:
fld qword [rax+rcx*8-8] ; quad word, n-1 is last subscript
fmul qword [rbx+rcx*8-8] ; now have x[i]*y[i] in C
in cross:
Note addresses passed, so to do z[0] = 0.0
zero: dq 0.0
fld qword [zero] ; value of zero loaded
mov rcx, [z] ; z: has address of callers z array
fstp qword [rcx] ; can not say qword [[z]]
; add 8 to rax for next value
; rax has base address of x
; rbx has base address of y
; rcx has base address of z
mov r8,[m] ; loop m=0 .. m<n
mov r9,[j] ; inner loop j=0 .. j<n
mov r10,[k] ; computed if ...
fld qword [rax+8*r9] ; x[j]
fmul qword [rbx+8*r10] ; x[j]*y[k]
fadd qword [rcx+8*r8] ; z[m]+x[j]*y[k]
fstp qword [rcx+8*r8] ; z[m] = z[m]+x[j]*y[k]
fld qword [sign]
fchs
fstp qword [sign] ; sign = -sign
All referenced files may be copied to your directory using:
Replace xxx.x with the file you want.
cp /afs/umbc.edu/users/s/q/squire/pub/download/xxx.x .
when working: submit cs313_squire proj2 math_64.asm
I do not know how to use .asm functions with other languages, yet
for those who are not familiar with "C", here are more languages
with math_64.??? and calling program in that language.
math_64.py3
test_math_64_1.py3
tesst_math_64_1_py3.out
test_math_64.py3
test_math_64_py3.out
math_64.cpp
test_math_64.cpp
test_math_64_cpp.out
test_math_64.java dot cross in here
test_math_64_java.out
Here is a very large conversion of matrix times vector multiply
from C to .asm
Large because I used much debug print, almost every access and
almost every operation printed with debug print.
I suggest lots of debug print while developing a program.
Then, after it works, comment out debug print rather than
delete debug print. Thus, 10 years later when you want to
make changes, you can easily turn debug print back on.
mat_vec.c source code to convert
mat_vec_c.out to check .asm
The .asm as developed with much debug print:
mat_vec_64.asm source code converted
mat_vec_64.out to check .asm
Finally, the last lines agree, many segfault during conversion.
Then comment out debug print and run again:
mat_vec_64n.asm source code converted
mat_vec_64n.out to check .asm
Finally finally make smaller by deleting comments:
mat_vec_64f.asm source code converted
mat_vec_64f.out to check .asm
Then, with confidence matrix time matrix was programmed:
mat_mat.c source code to convert
mat_mat_c.out to check .asm
mat_mat_64.asm source code converted
mat_mat_64.out to check .asm
With no debug print
You are to write a program that does NOT use "C" functions or libraries.
This project is based on lecture 9.
You may use system calls or BIOS calls from Lecture 9 to implement the program.
See hellos_64.asm for compiling, _start
To print a character from a2 array at index row=i, col=j
; array of bytes, characters size 41*21:
;
; 0 40 column subscripts
; ------- +1.0
; 0 | *** |
; rows | * * | 0.0
; index 20 |* *|
; ------- -1.0
; -pi 0 +pi
;
a2: resb 41*21 ; in section .bss
; in section .txt
mov rax, [i] ; a2+i*ncol+j is byte
imul rax, [ncol]
add rax, [j]
add rax, a2
mov rsi, rax ; address of character to print
mov rax, 1 ; system call 1 is write
mov rdi, 1 ; file handle 1 is stdout
mov rdx, 1 ; number of bytes
syscall ; invoke operating system to do the write
At end of j loop, just set rsi, a10 address of character 10 is line feed. copy lines above
To compile and run your program, use:
nasm -g -f elf64 plotc.asm
ld -o plotc plotc.o
./plotc
You only need to print one character at a time, rdx, 1 in syscall.
Print 10, '\n' at end of each line, end of j print loop.
Your program is to make a simple character plot of cos(x)
for x from -Pi to Pi, -3.14159 to 3.14159 in 41 steps, dx = 0.15708
Use 21 rows, middle row for cos(0.0) = 1.0,
top row for cos(Pi/2) = 0.0, bottom row for cos(-Pi)=cos(Pi) = -1.0
For each column plotting an '*' at row k = int(20.0 - (y+1)*10.0)
A very small version of the plot would look like:
* 9 columns, 7 rows
* *
* *
* *
* *
Compute cos(x) in your program y = cos(x) =
1 - x^2/2! + x^4/4! - x6^/6! + x^8/8!
OK to use code from horner_64.asm float
af: dq 1.0, 0.0, -0.5, 0.0, 0.041667, 0.0, -0.001389, 0.0. 0.000025
N: dq 8
XF: dq 0.0
This computes YF = cos(XF)
mov rcx,[N] ; loop iteration count initialization, n
fld qword [af+8*rcx]; accumulate value here, get coefficient a_n
h5loop: fmul qword [XF] ; * XF
fadd qword [af+8*rcx-8] ; + aa_n-i
loop h5loop ; decrement rcx, jump on non zero
fstp qword [Y] ; store Y
Then compute kf = 20.0 - (Y+1.0)*10.0 floating point
Then store k as integer: fistp qword [k]
Then compute double subscript, integer, k*ncol+j in rax
Then store star:
mov bl, [star]
mov [a2+rax], bl
Note: For printing mov rsi, rax // syscall (rcx for int)
add rsi, a2 // not [a2+rax] need address
If it runs to your satisfaction,
Then submit cs313_squire proj3 plotc.asm
The program in "C" is
See plotc_64.c for possible method
See plotc_64.outc "C" output
See plotc.chk Nasm output
See hornerc_64.asm for computing cos(x)
// plotc_64.c simple plot of cos(x)
#include <stdio.h>>
#define ncol 41
#define nrow 21
int main(int argc, char *srgv[])
{
char points[nrow][ncol]; // char == byte
char point = '*';
char space = ' ';
long int i, j, k, rcx;
double af[] = {1.0, 0.0, -0.5, 0.0,
0.041667, 0.0, -0.001389, 0.0, 0.000025};
long int n = 8;
double xx, y;
double dx = 0.15708; // 6.2832/40.0
// clear points to space ' '
for(i=0; i0; rcx--) y = y*xf + af[i-1];
k = 20 - (y+1.0)*10.0; // scale 1.0 to -1.0, 0 to 20
// k = (int)(20.0+(y+1.0)*(-10.0) in assembly language
printf("x=%f, y=%f, k=%d \n", x, y, k);
fflush(stdout);
points[k][j] = point;
xf = xf + dx; // XF = XF + DX0 in assembly language
}
// print points
for(i=0; iNasm code for loops to clear and print array of characters
array2_64.asm sample code
array2_64.out output
snippet of code, double loop, to clear array
(ultra conservative, keeping i and j in memory)
These 3 lines of "C" code become many lines of assembly
// clear points to space ' '
for(i=0; i<nrow; i++)
for(j=0; j<ncol; j++)
points[i][j] = space;
section .bss ; ncol=7, nrow=5 for demo
a2: resb 21*41 ; two dimensional array of bytes
i: resq 1 ; row subscript
j: resq 1 ; col subscript
k: resq 1 ; row subscript computed
SECTION .text ; Code section. just snippet
; clear a2 to space
mov rax,0 ; i=0 for(i=0;
mov [i],rax
loopi:
mov rax,[i] ; reload i, rax may be used
mov rbx,0 ; j=0 for(j=0;
mov [j],rbx
loopj:
mov rax,[i] ; reload i, rax may be used
mov rbx,[j] ; reload j, rbx may be used
imul rax,[ncol] ; i*ncol
add rax, rbx ; i*ncol + j
mov dl, [spc] ; need just character, byte
mov [a2+rax],dl ; store space
mov rbx,[j]
inc rbx ; j++
mov [j],rbx
cmp rbx,[ncol] ; j<ncol
jne loopj
mov rax,[i]
inc rax ; i++
mov [i],rax
cmp rax,[nrow] ; i<nrow
jne loopi
; end clear a2 to space
; j = 0;
; XF = X0; fld qword [X0] fstp qword [Xf]
From horner_64.asm use
fld qword [X0]
fstp qword [XF]
mov rax, 0
mov [j], rax ; j = 0
cos: mov rcx,[N] ; loop iteration count initialization, n
fld qword [af+8*rcx]; accumulate value here, get coefficient a_n
h5loop: fmul qword [XF] ; * XF
fadd qword [af+8*rcx-8] ; + aa_n-i
loop h5loop ; decrement rcx, jump on non zero
fstp qword [Y] ; store Y
; k = 20.0 + (Y+1.0)*(-10.0) fistp qword [k]
; rax gets k * ncol + j
; put "*" in dl, then dl into [a2+rax]
; XF = XF + DX0;
; j = j+1;
; if(j != ncol) go to cos jloop
; copy clear a2 to space
; in jloop renamed, use syscall print from hellos_64.asm
; add rax,a2 replaces dl stuff
; mov rsi, rax (moved up) replaces mov rsi, msg
; replace any len with 1
; after jloop insert line feed lf: db 10
; mov rsi, lf in lpace of mov rsi, rax
; use exit code from hellos_64.asm
; no push or pop rbx
in .data
af: dq 1.0, 0.0, -0.5 ; coefficients of cosine polynomial, a_0 first
dq 0.0, 0.041667, 0.0, -0.001389, 0.0, 0.000025
XF: dq 0.0 ; computed compute Y = cos(XF)
Y: dq 0.0 ; computed
N: dq 8 ; power of polynomial
X0: dq -3.14159 ; start XF
DX0: dq 0.15708 ; increment for XF ncol-1 times
one: dq 1.0
nten: dq -10.0
twenty dq 20.0
a10 db 10,0 ; need address of a10 for linefeed
ncol: dq 41
nrow: dq 21
spc: db ' '
star: db '*'
Your plotc.asm can NOT use printf or any "C" functions.
Thus you use global _start and _start: in place of
global main and main:
; compile using nasm -g -f elf64 plotc.asm <-- submit plotc.asm
; ld -o plotc plotc.o # not gcc
; ./plotc > plotc.out
; cat plotc.out
To do printout, use structure of clear to space, inserting:
mov rax,[i]
imul rax,[ncol] ; i*ncol
add rax, [j]
add rax, a2 ; a2 + i*ncol + j
; SYSCALL PRINT
mov rsi, rax ; address of character to output
mov rax, 1 ; system call 1 is write
mov rdi, 1 ; file handle 1 is stdout
mov rdx, 1 ; number of bytes
syscall
Your plotc.asm should contain, in this order:
; plotc.asm your name would be nice
section .data
; stuff from above
section .bss
; stuff from above
section .text
global _start
_start: push rbp
; iloop
; jloop
; blank=space a2 array
; end jloop
; end iloop
; XF = 0.0
; jloop
; compute cosine and put * in a2 array
; end jloop
; iloop
; jloop
; print a2 array
; end jloop
; end iloop
pop rbp
mov rax,60
mov rdi,0
syscall ; done, exit
; end of plotc.asm
when working: submit cs313_squire proj3 plotc.asm
Use ghdl or iverilog: (Cadence VHDL and Verilog license expired)
to use ghdl on linux.gl.umbc.edu, use Makefile_g
Makfile_g
to use iverilog on linux.gl.umbc.edu, use Makefile_ive
Makfile_ive
Both these Makefiles do both proj4 and proj5
For ghdl:
Use proj4.vhdl as the start of
project 4. Everything has been provided to build and test a
4-bit times 4-bit unsigned parallel multiply. In order to have
less VHDL, a "madd4" entity was created. The multiplier can now
be built from exactly four of the "madd4" entities.
(Slightly different from multiplier used in the lecture.)
The first "madd4" is in the file. You must code the three
remaining "madd4" and code the "dot" merge of "cout" with
the top three bits of the "sum", and the product bits "p".
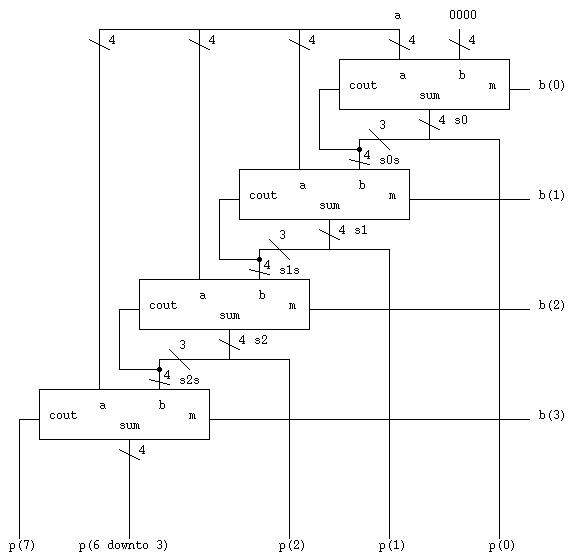 Notes: Each box is a madd4 entity.
The boxes should be labeled a0:, a1:, a2: and a3:.
The cout signals are named c(0), c(1), c(2) and c(3).
The sum signals are named s0, s1, s2, p(6 downto 3).
The dot where three wires join the cout wire is
coded in VHDL as s0s <= c(0) & s0(3 downto 1);
The s0s 4-bit signal goes into the madd4 'b' input.
The first 'b' input must be four zero bits, signal zero4.
The low order product bit, p(0) is the bottom bit
of s0 and is coded in VHDL as p(0) <= s0(0);
You need to type source vhdl_cshrc once per log on.
You need first to follow vhdl instructions below on cs313.tar.
For Verilog:
Use proj4.v as the start of
project 4.
Note some different signal names are used, s0s is b1 and
made with assign statements.
This is a modification of mul4.v
Fill in module madd4 using four madd modules.
Then instantiate four madd4 to build the circuit.
Your output should have correct 1 or 0 in place of "z"
proj4_v.chk
Other sample Verilog files
add4.v
mul4.v
Notes: Each box is a madd4 entity.
The boxes should be labeled a0:, a1:, a2: and a3:.
The cout signals are named c(0), c(1), c(2) and c(3).
The sum signals are named s0, s1, s2, p(6 downto 3).
The dot where three wires join the cout wire is
coded in VHDL as s0s <= c(0) & s0(3 downto 1);
The s0s 4-bit signal goes into the madd4 'b' input.
The first 'b' input must be four zero bits, signal zero4.
The low order product bit, p(0) is the bottom bit
of s0 and is coded in VHDL as p(0) <= s0(0);
You need to type source vhdl_cshrc once per log on.
You need first to follow vhdl instructions below on cs313.tar.
For Verilog:
Use proj4.v as the start of
project 4.
Note some different signal names are used, s0s is b1 and
made with assign statements.
This is a modification of mul4.v
Fill in module madd4 using four madd modules.
Then instantiate four madd4 to build the circuit.
Your output should have correct 1 or 0 in place of "z"
proj4_v.chk
Other sample Verilog files
add4.v
mul4.v
"using ghdl and iverilog
cp /afs/umbc.edu/users/s/q/squire/pub/download/Makefile_g .
cp /afs/umbc.edu/users/s/q/squire/pub/download/Makefile_ive .
Now work project 4:
Run the following commands to test your proj4.vhdl or proj4.v:
make -f Makefile_g
make -f Makefile_ive
You do the submit, submit cs313_squire proj4 proj4.vhdl or
submit cs313_squire proj4 proj4.v
check your products by hand or by .chk
proj4_g4.chk
proj4_v4.chk
Use ghdl or iverilog: (Cadence VHDL and Verilog license expired)
to use ghdl on linux.gl.umbc.edu, use Makefile_g
Makfile_g
to use iverilog on linux.gl.umbc.edu, use Makefile_ive
Makfile_ive
Both these Makefiles do both proj4 and proj5
Finish up the design and finish up the implementation
of a six bit spin lock.
You are given a starter VHDL file proj5.vhdl
Or, use the given starter Verilog file proj5.v
The spin lock is given by
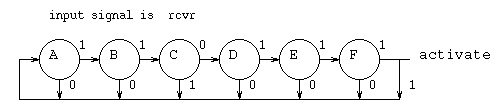 Use names A, B, C, D, E, F for the spin lock, there
is debug print in proj5.vhdl and proj5.v for testing.
Initialize all D flip flops to '0' except set A to '1'.
Be sure to compute "activate" along with the Ain, Bin, etc.
The test input has the name "rcvr" and has 10 entries.
The code to be detected is 6 bits in the middle.
The entity dff1 in VHDL, module dff6 in verilog, is used by
the spin lock is ready to use in
proj5.vhdl. The circuit symbol is:
Use names A, B, C, D, E, F for the spin lock, there
is debug print in proj5.vhdl and proj5.v for testing.
Initialize all D flip flops to '0' except set A to '1'.
Be sure to compute "activate" along with the Ain, Bin, etc.
The test input has the name "rcvr" and has 10 entries.
The code to be detected is 6 bits in the middle.
The entity dff1 in VHDL, module dff6 in verilog, is used by
the spin lock is ready to use in
proj5.vhdl. The circuit symbol is: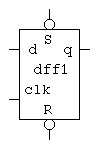 The module dff6 that is used by the spin lock is ready to use in
proj5.v. similar circuit symbol.
Your project is to finish the VHDL or verilog code for the spin lock.
Look for "???"
See lecture notes Lect 23
for method of converting a sequential circuit to digital logic.
The lecture notes have legal VHDL statements, e.g Ain <= ... ;
The Verilog uses Ain = ...;
Code the digital logic in VHDL and add the VHDL statements
into proj5.vhdl
Copy files into your vhdl directory with the following commands:
cp /afs/umbc.edu/users/s/q/squire/pub/download/proj5.vhdl .
Make changes the run:
make -f Makefile_g
For Verilog
Copy files into your vhdl directory with the following commands:
cp /afs/umbc.edu/users/s/q/squire/pub/download/proj5.v .
Run with
make -f Makefile_ive
Your output should have i=7 activate=1
proj5v.chk
proj5_vhdl.chk
in ghdl you get an error message.
Then submit cs313_squire proj5 proj5.vhdl or
submit cs313_squire proj5 proj5.v
The module dff6 that is used by the spin lock is ready to use in
proj5.v. similar circuit symbol.
Your project is to finish the VHDL or verilog code for the spin lock.
Look for "???"
See lecture notes Lect 23
for method of converting a sequential circuit to digital logic.
The lecture notes have legal VHDL statements, e.g Ain <= ... ;
The Verilog uses Ain = ...;
Code the digital logic in VHDL and add the VHDL statements
into proj5.vhdl
Copy files into your vhdl directory with the following commands:
cp /afs/umbc.edu/users/s/q/squire/pub/download/proj5.vhdl .
Make changes the run:
make -f Makefile_g
For Verilog
Copy files into your vhdl directory with the following commands:
cp /afs/umbc.edu/users/s/q/squire/pub/download/proj5.v .
Run with
make -f Makefile_ive
Your output should have i=7 activate=1
proj5v.chk
proj5_vhdl.chk
in ghdl you get an error message.
Then submit cs313_squire proj5 proj5.vhdl or
submit cs313_squire proj5 proj5.v
Files to download and other links
Course links
Last updated 11/27/2019