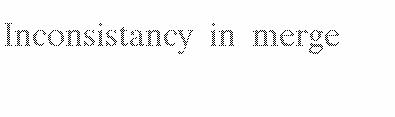
Figure 28: "Growth of Online Bibliographies" The numbers are order of magnitude estimates.
[information storage and retreival]Large-volume hypertext or macrotext emphasizes the links that exist among many documents rather than within one document. Typically, many people have contributed documents to macrotext and an institution is involved in maintaining the macrotext system. Maintaining the system involves maintaining both the interface to the documents and the connections among the documents. The many users of a given macrotext are searching for a few documents from a large set (see Figure "Macrotext"). Macrotext doesn't support the browsing of a single documentthat is a microtext facility. Traditionally, the term information storage and retrieval was used when talking about storing and retrieving many documents.
[managing the information explosion]Throughout history the information explosion has been perceived as outstripping people's ability to manage information. One partial solution has been to build archives of documents and to index the documents in a standard way. With the computer one can implement the archiving and indexing functions on a grand scale.
[18th century bibliographies]Bibliographies are pointers or links to documents. Simple bibliographies were published in the middle ages. By the 1700s, scholars had prepared bibliographies exhibiting a variety of approaches both by author and subject. The Repertorium is a subject index of the publications of the seventeenth and eighteenth centuries and took 20 years to publish, starting in 1801. However, the effort required to build the Repertorium was so great that it was hard to imagine how one could update such a subject index. In his annual report for 1851, the Secretary of the Smithsonian Institution in the United States called attention to the fact that `about twenty thousand volumes ... purporting to be additions to the sum of human knowledge, are published annually; and unless this mass be properly arranged, and the means furnished by which its contents may be ascertained, literature and science will be overwhelmed by their own unwieldy bulk.'
[Index Medicus]Index Medicus, which began in 1879, represented new methods of dealing with information and addressed the problem of updating indices. In 1874 John Billings began indexing the journals of the Surgeon General's Library in Washington, D.C. By 1875 he had accumulated tens of thousands of cards. Those from `Aabec' to `Air' were published by the Government Printing Office. The object of the publication, Billings wrote, was to show the character and scope of the collection, to obtain criticisms and suggestions as to the form of catalogue which will be most acceptable and useful, and to furnish data for the decision as to whether it is desirable that such a work should be printed and distributed. The implications of the last phrase become apparent from the letter that accompanied sample copies sent to prominent physicians around the United States. As Billings hoped, these physicians used their lobbying skills to help persuade Congress to appropriate the necessary funds to publish a full catalogue [Blak80]. When the first Index Catalogue was complete in 1895 it took 16 volumes. It listed some 170,000 books and pamphlets under both author and subject and over 500,000 journal articles under subject alone. Index Medicus was devised as a monthly periodical supplement to the Index Catalogue, listing current books and journal articles in classified subject arrangement. The publication of Index Medicus continues unabated today. One of the keys to the success of the Billings' approach was to obtain government sponsorship for the maintenance of the index.
[1930s]The notion of a computerized macrotext system begins in the 1930s, when Vannevar Bush started to argue the importance of applying modern technology to the production of information tools that would turn text into something like macrotext. Bush was imagining a scenario in which one individual dealt with the text of many other individuals by placing connections among the text items.
[national science advisor]Bush's hypertext machine, called memex, was conceived in the 1930s but not publicized until the end of the Second World War [Nyce89]. Bush was President Roosevelt's science adviser and overseer of all wartime research in the United States, including the nuclear bomb project. Memex was intended as a major new direction for technological investment in a peaceful society. At the end of the Second World War, Bush published several essays about memex, one of which appeared in the Atlantic Monthly, raising so much interest that it was republished in revised form in Life.
[vital information is lost]Bush firmly believed in the power of tools to facilitate information sharing. In a letter to a funding agency, he outlined how monies should best be spent to support research: I would not be surprised if developments of new methods ... and new ways of making ... material for research workers readily available, would have more effect on ultimate process ... than many a direct effort. In fact, I would go much further. Unless we find better ways of handling new knowledge generally as it is developed, we are going to be bogged down ... I suspect we now have reincarnations of Mendel all about us, to be discovered a generation hence if at all. Mendel's famous work in genetics was lost for generations because it was not published in a generally available source. The discoveries of other researchers were often wasted because of inadequate dissemination of results. Bush said that more research value would be obtained from an improved method to share research progress than would be obtained by any single research result.
[microfiche automated]Bush's memex machine, which was designed but never built, was meant to personalize libraries. Physically the device looked like a work desk with viewing screens, a keyboard, sets of buttons and levers (see Figure "Memex"). Storage of printed materials of all kinds was accomplished using microfiche. Pages of books were selected for viewing by typing an index code to control a mechanical selection device or by moving levers to turn page images of the selected item. Any two items in the memex could be coded for permanent association. Bush called this coded association a trail, analogous to the trail of mental associations in the user's mind.

[analog device]While the digital computer was being developed in the 1940s, and Bush was aware of those developments, he did not wish to incorporate digital features into his memex system. He felt that analogue features were somehow critical to the success of memex. Recent advances in computer systems, such as the mouse, make some analogue capabilities available and are related to the revived interest in memex-type devices. A practical memex needs high-resolution, large graphical screens and massive, inexpensive memory. Both of these features were better seen as analogue in the 1940s but have proven to be more readily available digitally in the 1990s.
[MEDLARS]The National Library of Medicine built the first macrotext computer system, drawing up specifications for a computerized retrieval system in the 1950s. Originally, the Library planned to graft the retrieval system onto its typesetting system for Index Medicus, but after repeated setbacks realized that priorities would have to be reversed such that the typesetting system became secondary to the retrieval system. The retrieval system was called the Medical Literature Analysis and Retrieval System (MEDLARS) and first operated successfully in the mid-1960s. It began with about 100,000 journal articles and in its first year processed thousands of queries. To obtain citations a health professional first conveyed an information need to a search intermediary at the National Library of Medicine. The search intermediary then formulated an online query, and a list of relevant citations was then printed and mailed to the health professional. The turn-around time was one month.
[1970s growth in online bibliographies]The 1970s witnessed the advent of inexpensive, long-distance
communications networks, inexpensive fast terminals, and inexpensive
large storage devices. These three factors combined so that users could
operate on a terminal in their office and get citations instantly in
response to their queries. There were over 300 bibliographic retrieval
systems by the late 1970s, storing tens of millions of citations and
receiving millions of queries each year. Access to these databases was
made available in the United States largely through commercial
suppliers. The growth in the number of bibliographic citations
available online and in the number of queries to these online systems
has been remarkable (see Figure "Growth of Online Bibliographies"). The
literature in these online systems is predominantly scientific and most
of the queries are for scientific material [Hall83].
Figure
28: "Growth of Online Bibliographies" The numbers are order of
magnitude estimates.
[1980s optical disks]In the 1980s optical disks became available. An optical disk is a few inches in diameter and the thickness of cardboard, yet one such disk can hold a thousand million bytes of information. Large document databases can be carried on a single optical disk. The cost of reproducing an optical disk is hardly more than the cost of reproducing a regular disk. Furthermore, personal computers can be equipped with an optical disk drive for about the same cost as any other disk drive. These characteristics of optical disks suggest that they will become the medium of the future for delivering macrotext. Many modern libraries have document databases available on optical disks, and these media are frequently and heavily used in those libraries.
[popularity of database on optical disk]The University of Liverpool Library has maintained for decades an online service to MEDLARS, the medical literature database. To access the database, patrons of the library must make an appointment with a librarian, usually days in advance of gaining access, and provide money to pay for the access. In the late 1980s the library acquired an optical disk version of the database. On each optical disk about one hundred thousand citations from the database can be stored. Since this equals about four months of citations, a new optical disk is shipped to the library each four months. Now patrons can go to a personal computer in the library and directly search the database. No librarian is needed. However, the system has proved so popular that queues of people form to use it. The patrons use the optical disk free of charge, and while the library must pay for the disks, a better service is provided at a lower cost.
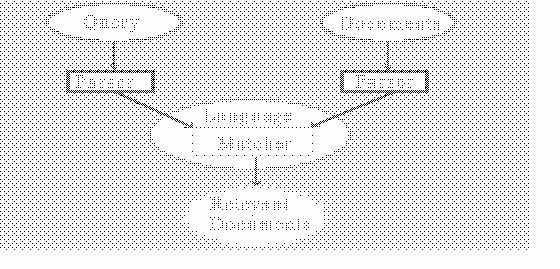
[parsing and matching]Macrotext systems are often constructed as database systems for which queries and documents enter the system and documents return to the searcher [Ston83]. If the language of queries and documents is not unified at some point, a match can not be made between queries and documents (see Figure "Query and Document Model"). Document indexing and retrieval can be seen as a combination of parsing and matching. Parsing moves a document or a query into another representation. In matching the parsed form of a query is compared to the parsed form of documents.
[strings versus word frequencies]The parsing of documents and matching of documents to queries can be based on the words in the documents and queries. In the simplest case the documents are unchanged in parsing, and the query is one string of characters which is directly matched against strings in documents. A more sophisticated process represents a document by the words with a certain frequency in the document. Queries are likewise represented as words which are then matched against the frequent words in each document.
[arbitrary strings]A string-searching, document retrieval system is one which allows the searcher to type an arbitrary string of characters and which returns the documents that contain that string. String-searching retrieval is on its surface disarmingly simple. It means storing the documents on a computer so that every string can be located. This approach is attractive because it takes advantage of massive digital technology and reduces the load on human indexers of documents.
[document representation]Computationally, string-search across a large document database can be very costly. The method of inverted indices captures much of the meaningfulness of the string approach, but more efficiently (the term `inverted index' is commonly used, although `index' alone would seem to do). A list of words is created, and adjacent to each word in the list is another list of pointers to documents that indicate which documents contain that word (see Figure "Inverted Index"). While there is overhead to creating and maintaining this list, given that the user specifies a word from the list, the documents in which that word occurs can be quickly retrieved.
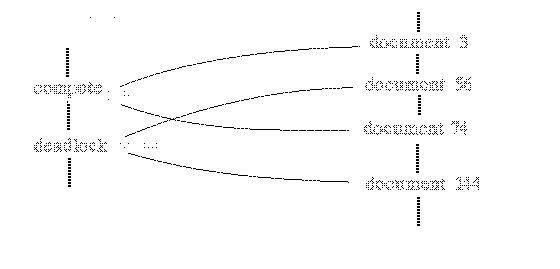
[Boolean queries]Inverted indices support queries with set operators. If the user specifies `$word sub x$ INTERSECT $word sub y$', then all the documents which have both $word sub x$ and $word sub y$ in them will be returned. This can be extended into arbitrary queries of words with UNION, INTERSECTION, and COMPLEMENT operators between the words. Given that only the lists of pointers need to be manipulated, simple set operations on the lists can very quickly produce retrieval results (see Exercise "Set and Logical Operators in Queries"). A Boolean query is a parenthesized logical expression composed of index terms and the logical operators OR, AND, and NOT. The effect of these Boolean operators is the same as the corresponding set operations UNION, INTERSECTION, and COMPLEMENT.
[adjacencies]Given that the pointers to documents indicate at what word position in the document the word occurs, queries about specific adjacencies can be posed. One can ask for all documents in which `$word sub x$ is within n words of $word sub y$'. If one wanted documents on the President's position on taxes, one might ask for `President within 4 words of taxes'.
[synonym problem]If one allows free-form English (or whatever the natural language of the users is) to be entered for queries, several problems can occur [Suda79]. The synonym problem: A searcher and a document author may use different terms to characterize the same concept. For example, `acoustic' and `sound' mean the same thing. The homonym problem: There are some words which look identical but have entirely different meanings. The word `tank', for instance, can mean either a container or an armored vehicle. The syntax problem: This is caused by using improper word order, such as `diamond grinding' versus `grinding diamond'. The spelling problem: The same word will sometimes be spelled in different ways. For example, `gauges' and `gages' may mean the same thing. The synonym problem is the most serious of these in practice.
[string search effective only on small databases]In an early assessment of full-text, string-search on a database of 750 documents, such searching by computer was significantly better than conventional retrieval using human subject indexing [Swan60]. More recent evidence, however, suggests that string-searching is only effective on small textual databases. String-search behaves poorly when the document space is of substantial size.
[a large experiment: only 20% retrieved]In one famous, large-scale study, a string-search system was loaded with 40,000 documents totaling about 350,000 pages of hard-copy text. The content of the documents concerned a large corporate law suit. Several lawyers and para-legals worked with the information retrieval system over many months and their satisfaction with the performance of the system was assessed. It was determined that the searchers expected to get about 75% of the relevant documents which the system contained. Searching was continued until the searchers said they were satisfied. Subsequent analysis showed that only 20% of the relevant documents had been obtained [Blai85].
[the synonym problem again]Why did the searchers believe they were getting 75 per cent of what they needed to recall, when in fact they obtained only 20 per cent? For example, one query concerned an accident that had occurred and had become the subject of litigation [Blai85]. The lawyers wanted all the documents pertaining to this accident and posed queries that contained the word `accident' in combination with a wide variety of other relevant terms. Subsequent study of the database found that many relevant documents did not refer to the event as an accident. Instead, those who had written documents arguing against a guilty charge on the accident tended to refer to an `unfortunate situation' or `event'. Sometimes relevant documents dealt with technical aspects of the accident without mentioning it directly. Depending on the perspective of the author, references to the accident took far different forms than the searchers had anticipated.
[explanation for result]String-search is difficult to use to retrieve documents by subject because its design is based on the assumption that it is a simple matter for users to foresee the exact words and phrases that will be used by authors. One needs to find the phrases that characterize exactly the documents one wants. This has never been shown to be possible on large textual databases. It is very difficult for users to predict the exact words that are used in relevant documents.
[frequency times rank equals constant]A document may be perceived as concerning the subject symbolized by a certain word within its content if that word occurs more frequently than could be expected in any randomly-chosen document. In this manner, words may convey information as to what a document contains. In a set of documents, each of which contains a certain word to the same extent, one expects that the occurrences of that word would be as though random within that set. If all words were to occur with equal frequency, the main concepts of a document could not be distinguished from the frequency of word occurrence. In fact, words occur in text unevenly. In general, where the rank of most frequent word is one [Zipf49].
[mid-frequency]The strategy for indexing a document by word frequency is to determine first the frequency with which each word in the document collection occurs. In one approach: the low-frequency words are then excluded as being not much on the writer's mind, and the high-frequency words are discarded on the grounds that they are likely overly general as indicators of document content. This leaves the mid-frequency words to characterize documents.
[high-frequency words in a document]To improve the value of word-frequency assessments of content many techniques have been elaborated. For instance, one technique generates mid-frequency phrases based on the adjacency of high frequency words. For instance, the words `word' and `frequency' occur with high frequency in this book but do not significantly characterize the book's content. However, the term `word frequency' occurs with mid-frequency and is a significant indicator of content. For another example, consider a library of documents on the topic of aerodynamics. Though the three words `boundary', `layer', and `flow' occur with high frequency in these aerodynamic documents, the term `boundary layer flow' occurs with mid-frequency in the collection. `Boundary layer flow' is an important index term for some documents, while the word `boundary' doesn't meaningfully characterize any of the documents.
[low-frequency words]Another technique maps low frequency words into synonym classes. Words which occur with low frequency in a document may either indicate that the document is not about the topic which that word symbolizes or may indicate a synonym group which is important to the meaning of the document. For instance, the word `querist' may only be used once in a document about about searching the literature, but as a synonym to the frequently used word `searcher', `querist' is significant.
[algorithm]One algorithm for word-frequency indexing follows: Identify all the unique words in the document set. Remove all common function words included in a `stop' list. This stop list includes articles, such as `the', prepositions, such as `of', and conjunctions, such as `and'. Remove all suffixes and combine identical stems. For instance, the words `searcher', `searching', and `searches' would be represented by the single stem `search' after the removal of the suffixes `er', `ing', and `es'. Determine sequences of words that form frequent terms. Determine synonyms for low frequency terms. Give a range of frequencies for terms to be considered for indexing. All terms that are within the range are index terms. Words are the basis of the indexing but in some cases they are combined into meaningful terms based on word frequency and co-occurrence. Since a word is a term, the algorithm concludes in step 6 by referring to terms only (see Exercise "Word Frequency").
[positives and negatives]Imagine that a searcher wants a book from the library about microcomputers. If every book that contains the word microcomputer is given to the searcher, then ideally all those documents would be relevant and no other documents would be relevant. The relevant documents that contain the term `microcomputer' are true positives, and the irrelevant documents without the term are true negatives. An ideal retrieval produces no false positives or false negatives (see Figure "Positives and Negatives"). In reality, however, a search such as the above would produce many false positives and false negatives. (*Figure 31::, "Positives and Negatives").
[effect of weights on retrieval]One method of reducing the false negatives or false positives is to weight terms based on their frequency of occurrence in each document relative to their total frequency in the document collection. For instance, if the document collection contains 10 documents, $document sub A$ contains the term `microcomputer' 20 times, $document sub B$, $document sub C$, and $document sub D$ each contain the term 10 times, and the other 6 documents don't contain the term, then the weight on the term `microcomputer' for $document sub A$ is 2/5, for $document sub B$, $document sub C$, and $document sub D$ the weight is 1/5, and for the other 6 documents the weight is 0. If retrieval for the query `microcomputer' requires that a document contain the term microcomputer with a weight greater than 1/5, then false positives are likely to be lower than if the weight has to be simply greater than 0. terms
[weights on terms]To exploit the good features of very frequent and infrequent terms, while minimizing their bad ones, a weighting scheme can be used. Assume that all the terms in a set of documents are stored in a vector. Any document might be represented by this vector where each term is replaced by a number between 0 and 1. Each number testifies to the extent to which the corresponding term characterizes the document at issue.
[discrimination analysis]Discrimination analysis ranks terms in accordance with how well they are able to discriminate the documents of a collection from each other [Salt75]. The best terms are those which achieve the greatest separation. If each document is described as a weighted vector of terms, one can define a distance between two documents as the distance between the vectors. A number of document retrieval studies indicate that in a good set of document vectors the average distance between pairs of documents is maximized. The highest weight is assigned to those terms in a vector which cause the maximum separation among the document vectors.
[relevance and distance]Human information processing involves conceptual matching, for which relevance is an important aspect. The more relevant two concepts are, the smaller the conceptual distance between them. When concepts are represented by vectors, conceptual distance can be measured by the distance between the vectors. When a document and a query are each represented by a vector, the distance between the two vectors can be used in determining whether or not the document is relevant to the query (see Exercise "A Relevance Formula"). In other words, for a document retrieval system, distance can be used to determine which documents should be retrieved in response to a query.
[example computation]In an information retrieval system a document is returned to a query when the distance between the document and query is under some threshold. One example of a distance between a weighted document vector and a weighted query vector subtracts corresponding weights and then adds the absolute values of those differences. Thus if $document sub 1$ =(0.1, 0.7, 0.3), $document sub 2$ = (0.2, 0.5, 0.1), and query = (0.1, 0.6, 0.4), then the distance between document and query is given by distance(query,$document sub 1$) = 0.0 + 0.1 + 0.1 = 0.2 distance(query,$document sub 2$) = 0.1 + 0.1 + 0.3 = 0.5. In this case the query is closer to $document sub 1$ than to $document sub 2$. If the retrieval system returned documents which were within a distance of 0.3 from the query, then $document sub 1$ would be returned and $document sub 2$ would not be returned.
[better than manual]Some evidence indicates that word-frequency text analysis is as effective as manual indexing. A simple indexing process based on the assignment of weighted terms to documents and queries has, at times, produced better retrieval results than a more sophisticated manual document analysis [Salt83]. Furthermore, in many cases manual indexing is not feasible. analysis
[reduction in search time]The cost to determine the distance between document vectors and a query vector is prohibitive for large document collections. Each time a query is posed, the retrieval system would have to compute the distance from the query to each document. The cost of search for close documents can be reduced by clustering documents into classes, where the elements of each class are within a prescribed distance of one another. Each cluster is described by one vector. The search strategy simply finds the cluster vector which is closest to the query and then returns the documents in the cluster. documents
[example computation of cluster]One way to build clusters is to first determine the distance between all pairs of document vectors in the document collection. Then any two document vectors whose distance is below some threshold are included in a cluster. Next a cluster centroid is defined as a vector that is an average of the other vectors in the cluster (see Exercise "Discrimination Analysis"). For instance, if $document sub 1$ and $document sub 2$ are the only two documents in a cluster, $document sub 1$ =(0.1, 0.7, 0.3), and $document sub 2$ = (0.2, 0.5, 0.1), then the centroid for that cluster is (0.15, 0.6, 0.2).
[example benefit in search cost]Clustering reduces search time. If a document collection has one million documents and two equal-sized clusters are made, then after the search has found the closest cluster to a query, there still remain 500,000 documents to filter. On the other hand, if the collection is divided into 100,000 clusters, then retrieving the cluster closest to a query requires 100,000 computations. By defining the centers of clusters it is possible to assess the similarity among clusters and to add another level of organization to the classification of sets of documents [Salt83]. For example, given the 100,000 clusters, grouping them into tens, and repeating this process, one gets a hierarchy of clusters in which the top level has 10 clusters, the second level has 100 clusters, and so on. In retrieval one would never need to do more than a few computations of distance between the query vector and the centroid of a cluster in order to find a small cluster of documents which was close to the query.
[initial cost versus subsequent benefit]Cluster-based strategies need substantial initial investment of computer time to construct the hierarchy of document clusters. This initial investment pays dividends in reducing the effort involved at search time in retrieving documents in response to each request (see Exercise "Hierarchy Search Benefit"). For a fixed document collection which is frequently accessed, the benefits of clustering are substantial.
[role of indexing language as ordering system]The effectiveness of a retrieval system is largely dependent upon the document classes in it. These classes may be based on terms from an indexing language which semantically relates terms, is used to index documents, and supports queries [Lanc72]. An indexing language is an ordering system which is `any instrument for the organization, description, and retrieval of knowledge that consists of verbal or notational expressions for concepts and their relationships and which displays these elements in an ordered way.' [Dahl83]
[pre and post coordination]In a string-search system the searcher who wants to find documents about a complex multi-word concept, like `online bibliographic system', could request all documents that contain the words `online', `bibliographic', and `system'. Each retrieved document contains the three words, which the search has post-coordinated. A paper index does not, however, readily support such post-coordination. If the user were to search in the paper catalog under the term `online', make a list of the documents, then search under the term `bibliographic', make another list of the documents, and determine the documents which both lists have in common before continuing with the term `system', the user would be tired. Accordingly, for paper indices concepts are pre-coordinated, and a concept like `online bibliographic system' is directly represented with a single term.
[specificity]Specificity in indexing refers to a semantic property of index terms: a term is more or less specific as its meaning is more or less detailed and precise. Index term specificity must also be considered from the view of what happens when a given index vocabulary is actually used. As a document collection grows, the descriptions of some documents may not be sufficiently distinguished because some terms are frequently used. Thus it may be the case that a particular term becomes less effective as a means of retrieval, whatever its actual meaning. A frequently-used term may thus function in retrieval as a non-specific term, even though its meaning may be quite specific in the ordinary sense [Jone80].
[query]A query to a macrotext system whose documents have been indexed with terms from an indexing language naturally supports retrieval with queries expressed in the terms of that indexing language. In the simplest case, the user presents a single term to the system, and the system returns those documents which have been indexed with that term. More generally, index terms are combined with set or Boolean operators.
[personnel costs in indexing]When maximum specificity is sought in the indexing procedure, the index terms representing a document often represent significantly distinct concepts. To use an indexing language in the indexing of documents typically requires a large investment of intellectual effort. At the National Library of Medicine, which indexes about 300,000 documents per year, about 100 people are devoted to indexing. About a dozen index terms are assigned to each document, but an indexer is expected to spend only 15 minutes on each document. The indexing staff includes a quality control unit. Similar situations apply at other large information services which index documents.
[term matching]Aids to indexing have been developed. In one strategy, an index term from a thesaurus is suggested for a document, if it is in the title of the document [Rada79]. While this approach seems overly simple, it can provide a guide to human indexing, when the thesaurus has been developed to coincide with terms in titles of documents. Other strategies extend the term matching so that the occurrence of parts of an index term in the abstract of a document suggest that index term be applied to the document.
[definition of thesaurus]One of the most popular forms for an indexing language is a thesaurus. While a thesaurus in the lay use of the word usually suggests an alphabetically sorted list of terms with attached synonyms, in the library science field this is often expanded. A thesaurus is a set of concepts in which each concept is represented with at least synonymous terms, broader concepts, narrower concepts, and related concepts [Coun80]. A term is a word or sequence of words that refers to a concept. For instance, `shortness of breath' may be considered a term when discussing symptoms of patients. Each concept may be associated with one term that serves as the name of that concept.
[example thesauri]Popular thesauri for classification of library books are the Dewey Decimal System and the Library of Congress Subject Headings. A popular thesaurus for general use is Roget's Thesaurus [Roge77]. Roget's Thesaurus has several hierarchical levels so that, for instance, `general form' is narrower than `form' which is, in turn, narrower than `space', but synonyms are only given for the narrowest terms.
[link types]The relations or links broader, narrower, related, and synonymous have been defined for thesauri [Coun80]. The relation `broader' can mean: Class inclusion, such as neoplasm is a disease. Whole-part, such as hand is a part of arm. Other connected concepts, such as `electron tube' is broader than `characteristic curve of an electron tube'. The relation `narrower' includes the reverse relations of those listed for `broader'. Two terms are considered to be `related', if they are related but neither is `broader' than the other. `Related' may be used to identify terms that are related to each other from a certain point of view, such as usage, action, or process. The `synonymous' relation points to terms that mean the same thing. The standards for thesauri restrict the relations to little more than the above.
[classification structure]From a computer scientist's perspective `thesaurus' and `classification structure' might mean the same thing, but from a librarian's view they have traditionally had different meanings. To a librarian a classification structure is a listing of terms that depicts hierarchical structure [Lito80]. For instance, a classification structure would show the terms `disease', `joint disease', and `arthritis' one after the other on the page with indentations and numberings to indicate `narrower' relationships (see Figure "Classification Structure"). The terms in a thesaurus are alphabetically, rather than hierarchically, sorted. 1. disease 1.1. joint disease 1.1.1. arthritis (*Figure 34::, "Classification Structure"). structure
[converting between thesaurus and classification structure]As computers become more common in library work, the difference between an alphabetically-sorted list (thesaurus) and a list sorted by hierarchical position (classification structure) becomes less critical, andd each is more likely to be viewed as a different representation of the same information [Dahl80]. From a thesaurus, where each term points to its conceptual parents and children, a computer program can readily generate a classification structure. Furthermore, a classification structure could incorporate with each entry a list of synonyms and related terms, and in that case a computer could generate a thesaurus from a classification structure.
[how to build a thesaurus]The thesauri for large online bibliographies are massivethey may contain over one hundred thousand concepts. How are these thesauri constructed and maintained? What is the relationship between indexing and thesaurus maintenance? Can word frequency information be useful in thesaurus maintenance?
[thesaurus and index experts]An institution which indexes many documents and maintains a large thesaurus may have an indexing staff of one hundred people and a thesaurus staff of ten people. The thesaurus group consists of experts in the domain of the literature to be processed. These experts have a grasp of the terminology and semantic subtleties of the subject field. The thesaurus group is responsible for collecting index terms, and making the thesaurus as up-to-date as possible for the index group. The index group indexes the documents according to the latest version of the thesaurus and suggests new index terms to the thesaurus group.
[index first or construct thesaurus first?]In the development of a macrotext system, one dilemma is whether to build a thesaurus first and then use it for indexing the documents or to index the documents by free terms and then construct the thesaurus after accumulating a good number of these free terms. As is often true in life, the middle ground is particularly attractive, and that means in this case building a thesaurus and indexing documents hand-in-hand. a thesaurus
[how to add terms to a thesaurus]To build a thesaurus and index documents simultaneously requires both selecting a set of documents and creating a thesaurus around which to begin. Then an indexer scans a document and chooses in a free-form fashion a set of terms to characterize that document. In case a term is not available in the thesaurus, one of the following three approaches may be taken: [Suda79] If a synonymous term is available in the thesaurus, then the thesaurus experts should be asked to include this synonym in the thesaurus. For example, if the term `lathe' is available in the thesaurus but the indexer has chosen the synonym `turning machine', then `turning machine' should be added as a synonym to `lathe'. If the indexable concept can be broken into parts which are in the thesaurus, then this breakdown should be made and the thesaurus might be augmented to indicate the relation which exists between the component terms. For instance, if `hydrostatic thrust bearings' is initially chosen to describe the document but the index only has `hydrostatic bearings' and `thrust bearings', then the document is indexed under both terms and the thesaurus might be augmented to indicate that these two types of bearings are related. If steps 1) and 2) do not produce index terms from the thesaurus, then a check is made for terms in the thesaurus which are broader than the one chosen by the indexer. If the initial thesaurus is well-designed, then any new term must, at least, be able to fit under some pre-existing broader term. So the indexer next asks the thesaurus group whether the indexer's term should be added to the thesaurus as a `narrower' term or whether the existing `broader' term itself should be used. This hybrid method of free-text and controlled vocabulary for thesaurus construction depends on both the thesaurus group and the index group. Purely intellectual attempts to produce perfect thesauri don't work. Feedback from indexers must guide the development of a thesaurus [Wess79].
[frequency implies value]Terms that frequently occur in a document collection are candidates for inclusion in the thesaurus for that collection. Conversely, a term which rarely occurs in the collection is unlikely to make a good thesaurus term. The frequency of usage of thesaurus terms by indexers can itself serve as a guide to thesaurus maintenance. If a term is frequently chosen by indexers, then terms more specific than it should be added to the thesaurus. A thesaurus term which is never used by indexers is a candidate for removal from the thesaurus.
[suggest thesaurus relations]Determining the relations among thesaurus terms is particularly difficult. Association by frequency of co-occurrence between two terms, x and y, suggests relationships, such as: [Jone71] a) x and y are synonymous, b) x is narrower than y, and c) x and y are members of a compound term, like `flip flop'. For instance, x may be narrower than y, if the number of documents containing y is much larger than the number containing x. Word-frequency thesaurus building is not feasible by itself. The identification of terms and relationships by word-frequency methods may be useful as pre-processing that results in a list of important terms and potential relationships between them. These relationships can then be combed by people to establish which relationships are cognitively meaningful.
[requirements for retrieval interface]The interface to a retrieval system must make apparent all the relevant options to a user [Mitt75]. For instance, since a retrieval system must allow documents to be retrieved based on author or date, one option on the interface should lead to an alphabetically-sorted list of author names. The interface should make it easy for searchers to request documents written across some period of time, for instance, one might ask for all documents published between January and July of 1985. However, the most complex part of the retrieval interface must support access by content descriptions. How can the searcher be guided into ways of requesting documents on an arbitrary topic?
[menu depth]When a very large thesaurus is accessed via a computer screen, the user may need to change the contents of the screen many times to find the terms for a query. This difficulty has been substantiated in experiments on the impact of depth of menu on performance. Those results indicated that performance time and errors increased as the hierarchical levels of the data in the menus increased [Sepp85]. Thus the user should be allowed parallel modes of presentation of data and not just one menu.
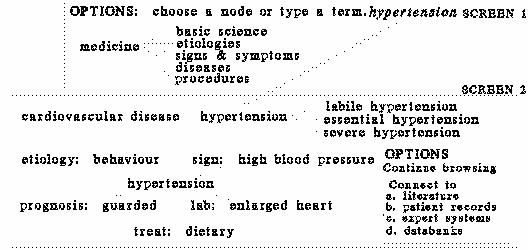
[graphical screen]A new generation of systems depends on graphical interfaces, menus, and natural language processing to help end-users exploit the access points of the macrotext system. A fictitious screen is presented in which a user is looking for articles about hypertension and its genetic etiology. The user first has the choice of browsing the thesaurus or entering a term directly. Say the user enters the term `hypertension'. Next the conceptual neighborhood around hypertension appears on the screen. That neighborhood includes both the `broader' and `narrower' terms for hypertension and a constellation of terms connected by `etiology', `prognosis', `treatment', and other such links that are appropriate for the disease hypertension (see Figure "Retrieval Interface for a Richly-Connected Term").
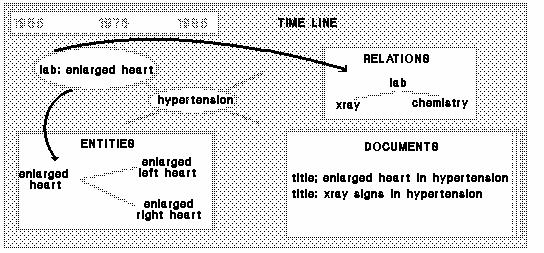
[further graphical views]If the user now chooses to pursue the `lab link' of hypertension, there appears another screen which shows both specific `lab links', namely `xrays' and `chemistry', and specific `enlarged heart' terms (see Figure "Expansion of Relations"). Simultaneously there appears: 1) a time line and 2) the titles of the documents. Users can interact with the time line to specify the dates of publication for retrieved articles.
[querying strategy]A common querying strategy is to submit first a broad request and then refine the request by adding conditions, until a reasonably small set of relevant documents is returned [Fide84]. This trial-and-error process can be very tedious when performed by a novice who is not familiar with the way documents are indexed. Further, when no document matches all the conditions of a query, there is no knowledgeable way of telling which documents might be close to the query.
[need for user models]Many interfaces to information systems attempt to be all things to all people. They have not been designed with a specific target audience or user model in mind. Human factors research has shown the importance of iterative design with a group of subjects drawn from the intended population of users. When an interface is tailored to one narrow population, that population can accomplish a search with relatively little training [Case86]. The user who can understand the principles of the system is better able to effectively present complex queries. Conversely, for simple queries a more mechanistic view of the system seems to be adequate for successful searching.
[accomodators versus assimilators]Pursuant to psychological testing, people can be categorized as `accomodators' or `assimilators'. Accomodators solve problems in intuitive, trial-and-error ways, while assimilators prefer to reason and reflect. In one study of novice MEDLINE searchers, assimilators were consistently more successful than accomodators. Distinct training programs and interface styles could be designed for these different types of users.
[role of search intermediary]Novice users often pose natural language queries in writing to professional search intermediaries. The search intermediary then accesses the document database and generates queries. While novices often have difficulty with the mechanical and conceptual aspects of searching, search intermediaries are experts and use such systems easily [Borg86]. These differences in behavior might be due to effects of training, experience, frequency of use, and knowledge about information structures.
[role of training]If macrotext systems are to be widely used, then many users must be able to satisfactorily search without the intervention of a search intermediary. Users may, however, be expected to undergo a brief training period. In one study, novice users were given 4 hours of training, and then their performance was compared to that of search intermediaries. These `trained novices' obtained results similar to those of the search intermediaries. Furthermore, the novices felt more committed to reading the relevant literature, because they had done the search themselves.
[evaluating several aspects]Evaluation takes several forms for a macrotext system. What is put into the system has enormous impact on both the creators and accessors of the documents. The indexing and indexing language should also be evaluated. Most carefully studied has been the quality of retrieval from a given system. Recall and precision are the popular devices for evaluating retrieval from a macrotext system.
[the dead document]The decision about what documents to include in an information retrieval system is crucial to the perceived utility of the system. There are major practical, often financial but sometimes also technical, limits to what documents any given information system can hold [Kraf73]. Including a document in a macrotext system means that a link exists between that document and the users of the macrotext system. A document lives to the extent that it is somehow used. In this sense, the decision to NOT place a document into a macrotext system is to hurt the document. If the document is also not available anywhere else, it is effectively dead.
[heuristics for acquisition]The acquisition of documents for a macrotext system seems to be largely controlled by rules of thumb. Clearly, customers should be satisfied, and the budget should be balanced, but how these goals should be obtained is less clear. Methods for selecting documents to include in an information retrieval system may be scientific, political, or economic in orientation. Within the life sciences alone there are several information systems, and each has its own method of selecting journals [Garf85]. One of the criteria for a journal to be indexed is that it has significant circulation, though given that a significant circulation may be difficult to achieve before the journal is indexed, a kind of vicious circle is created.
[citation analysis]A variety of quantitative tools has been used in the determination of journal quality. Citation analysis has been repeatedly recommended as a tool for journal selection, [Dhaw80] and has also been applied to the elucidation of specific features of a document, such as its methodological rigor. One analysis of documents notes that the appearance of a colon `:' in the title of a document suggests scholarly content [Perr85].
[publish or perish]The popular dictum in academia is publish or perish. By implication the authors best fit to survive in academia are those who publish the most. Extending this notion to the assessment of journals, one might expect that the more important a journal the more frequently the authors in it publish. Various experiments do not, however, confirm this hypothesis but rather indicate that the papers in good journals are written by authors who publish in other good journals [Rada87]. This suggests that the `publish or perish' mandate is sound only when qualified as `publish in good places or perish' (see Exercise "Publish").
[journal acquisition for Index Medicus]There are about 20,000 biomedical journals in existence. Of these, about 3,000 are indexed in Index Medicus. When a medical library tries to decide what journals to purchase, the library typically refers to Index Medicus and will avoid subscribing to a journal which is not indexed. Circulation is thus related to indexing. When authors write good papers, they often prefer to publish them in journals which are indexed. In the medical field, a scholarly paper which appears in a non-Index Medicus journal is much less likely to reach its audience than if it appeared in an Index Medicus journal, so publishers and editors of a new journal go to great lengths to attain a position in Index Medicus. Membership in the index may be necessary for membership in other critical groupings, such as the high-circulation grouping, the quality-papers grouping, and the often-read grouping [Rada90a].
[criteria include quality]Until 1964, journal selection decisions at Index Medicus were made by the Head of the Indexing Section. However, efforts were continually made to provide some rationale for the inclusion or exclusion of articles. These attempts usually reiterated a concern with the inclusion of `quality' articles (without defining quality) and admonishments as to what should not be indexed [Kare67]. In 1964, due to the recognized impact of Index Medicus on the selection of journals for acquisition by libraries, a panel of experts was constituted and given the task of deciding which journals should or should not be indexed. The panel produced six general criteria (see Figure "Journal Selection Criteria"), [Bach78] which stressed that the people associated with the journal are reputable and that norms of publishing are obeyed. Sponsorship of the journal by a professional organization of recognized status in a given discipline or subject area. Sponsorship by a national academy or national institute. Existence of an active editorial board consisting of knowledgeable and critical referees with high professional standing. Regular contributions to a journal by leaders in the subjects to which the journals address themselves. Strict adherence to an established format in presentation of methodology, tables, graphs, references and other data. Publication policy that appears in the journal.

[indexing evaluation]When human indexers assign index terms to a document, how consistent, accurate, or thorough are they? If the best experts can perform an indexing which is considered ideal, then how will one test any other indexing against the ideal? The validity of indexing is not simply the exact matches between an ideal and a test indexing. When a thesaurus is used, terms from the test indexing which are close in the thesaurus to terms from the ideal set should be considered more correct than terms which are not close (see Exercise "Validity of Indexing").
[thesaurus evaluation]One can axiomatize the desirable properties of a good thesaurus based on psychological rules. A standard method of portraying the hierarchy in a thesaurus to a user is for any concept to list all the `narrower' concepts in a menu. As a novice searcher traverses a thesaurus in search of appropriate query terms, the searcher's short-term memory limitations make it desirable that each concept have a handful of narrower concepts so that the menu display is neither too sparse nor too cluttered [Lee85]. The number in a handful varies with the application and user, but as a rule of thumb falls roughly between 4 and 18 with the ideal being 7. The number of narrower terms from any given term is called the branching factor for that given term. A quantitative assessment of a thesaurus can be made of the extent to which the thesaurus maintains a good branching factor. Thus thesaurus $T sub 2$ is better than thesaurus $T sub 1$, if $T sub 2$'s branching factor is more consistently about 7 than is $T sub 1$'s branching factor.
[cognitive model]Searchers on a macrotext system may have many different notions of what constitutes a relevant document. One person may want the most recently published document. Another may want a document that is frequently cited by other people. The cognitive model of a searcher is necessarily complex. Given some way to measure relevance (and this measure is the hard one), retrieval performance can be easily assessed with recall and precision measures.
[recall and precision]If the document collection is separated into retrieved and not-retrieved sets and if procedures are available for separating relevant items from nonrelevant ones, then Recall and Precision are defined as: Recall measures the ability of a system to retrieve relevant documents, while conversely, precision measures the ability to reject nonrelevant materials. Everything else being equal, a good system is one which exhibits both a high recall and a high precision.
[relevance is subjective]Measures like recall are based on a person's assessment of relevant and nonrelevant documents. Some people consider these subjective assessments unreliable. Among other things, a document may be relevant by content, by timeliness, by cost, or many other factors. However, in one well-controlled comparison of the ability of humans to consistently judge the relevance of documents, humans were able to make such judgements consistently [Resn64]. While the internal decision-making apparatus is clearly complex, humans are able to produce consistent decisions about document relevance under certain circumstances.
[single value based on correlating rankings]One measure of effectiveness of a document retrieval system assigns a single number to the value of retrieval [Swet69]. This contrasts with the popular covarying pair of measures of recall and precision. A computer system can assign values or scores to documents, the scores attesting to the closeness between a document and a query. Likewise, people can be asked to make the same assessments. From these scores can be derived rankings, and the rankings may be compared with a correlation coefficient. The assumption here as for recall is that human experts are the gold-standard of performance. The evaluation of a system's retrieval ability compares the system's ranking with the ranking of human experts. The higher the correlation, the better the system is performing.
[companies need macrotext systems]Many organizations maintain macrotext systems, as do in fact some individuals. Effective and efficient document indexing and retrieval may be critical to a company's success. Often the documents are classified simply by author, date, and title. Retrieval by more specific content is typically difficult, unless indexing by word patterns or an indexing language has been done.
[special needs of text]Text is unlike other types of data in the complexity of its structure. For the purposes of storage, a text may be regarded as a very long string. For retrieval purposes, however, substrings of the text must be identified. Although the data structuring capabilities of relational database systems are well adapted to support complex structures, they provide few built-in tools for the analysis of text strings. Furthermore, the modeling process appropriate for building a relational database is not necessarily appropriate for building a text database. A text system must concern itself with the document, the part of a document which is to be searched, and the set of documents which are to be returned to a searcher. A text database must support definition of text structures, retrieval of document sets, formatting of retrieved documents, control of document terminology, and addition of documents.
[STAIRS structure]STAIRS is a storage and information retrieval system marketed by IBM. IBM sells the software separately from any document database to go with STAIRS. The system includes utility programs for database maintenance and a retrieval system. The database structure includes a dictionary, an inverted file, a text index, and text files. The text files are the actual documents which users want. The dictionary contains all words that are in the document set. The inverted file says for each occurrence of each word exactly where it occurs relative to paragraph, sentence, and word number. The text index allows some documents to be marked private.
[STAIRS search]Search statements in STAIRS may include logical and proximity operations among words. For instance, the logical command `Computer OR Machine' would retrieve pointers to documents that contained the word Computer or the word Machine. The proximity operator ADJ means that two words must be adjacent in the document, while the operator WITH means that the two words are in the same sentence. Specific fields within the database can be defined, and the user can search on these in traditional database query ways.
[evaluation of systems]Dozens of major, commercial text database systems are available. An extensive evaluation was recently performed on three of these systems: BASIS, BRS, and STATUS [Bain89]. Each of these well provides all the basic functions required of large text database systems. On the majority of tests the performance of the three systems was essentially identical, though, in comparing one system to another, the evaluators did criticize the BASIS interface, the BRS recovery facilities, and the STATUS retrieval techniques.
[DIALOG]Bibliographic systems typically contain citations to documents. A citation to a journal paper, for instance, may include the paper's title, journal name, journal pages, date of publication, authors, abstract, and index terms. DIALOG is an online bibliographic system with approximately 300 different document or citation databases. The system is based on an inverted file design. In response to a search statement, the system first returns sets of document pointers. The user can operate on these sets and at any point ask to see the citations associated with the reference numbers. The following is a sample of an interaction on DIALOG. Notice that the system returns all data in uppercase.
[initiation]The first step for a DIALOG user is to gain access to the system (see Figure "DIALOG Startup"). One way to begin is to telephone a computer network (TELENET in this example) and then specify a code number (202 13E in this example). DIALOG then prompts the user with a question mark after a logon and welcome message. If the user types `begin number', the system enters the database identified with `number'. In this example the database number 202 is entered which refers to `Information Science Abstracts'. Dialing TELENET: .9 429 7800 Carrier Detected ..Online! TELENET 202 13E DIALOG INFORMATION SERVICES PLEASE LOGON: Welcome to DIALOG ?b202 File 202:INFORMATION SCIENCE ABSTRACTS 66-86/MAY (C. IFI/PLENUM DATA CO. 1986)

[search]The search strategy for a DIALOG session involves Boolean queries over terms in the database. A search statement begins with an `s'. In the example (see Figure "DIALOG Search") the first search statement is `s information and systems'. DIALOG responds with a list of how many citations contain each of the terms in the search and the result of the Boolean operation. In this example, the database has 94,090 citations with the term `information' in them, 34,978 with the term `systems' in them, and 34,359 citations that have both terms. The query `information(1w)systems' asks for the citations which have the term `information' within one word of the term `systems' in the citation. While 34,359 citations contained both terms, only 13,584 had the two words adjacent. The expand command (abbreviated `e') asks for a listing of the terms in the index dictionary in alphabetical order around the term given in the expand command. For instance, `e information' returns the list shown in the Figure. These terms have been used to index documents in the `Information Science Abstracts' database.

[retrieved citation]To actually retrieve specific citations, users enter print requests. Each request may have several options. The parameters `6/4/1' request data for search statement 6, with printing format 4, and for the 1st citation retrieved (see Figure "DIALOG Retrieval"). Information retrieved includes the title (TI), the authors (AU), the source (SO) which in this example is the journal Scientometrics, the abstract (AB), and the descriptors (DE) used to describe the contents of the article. The FN field notes the particular database from which the article has come. The full abstract in English is available for many articles.

[billing]To use a system like DIALOG one must have an account with DIALOG. The costs of these accounts is substantial; one can expect to pay about 100 dollars per hour for online access to the database, the charge depending on the particular database. As one leaves a database and enters another database still within DIALOG, one gets a summary cost statement for the exited database (see Figure "DIALOG Costs"). In the example, the command `b 13' signals a move to another database. What is first returned is a billing statement. The interaction with `Information Sciences Abstract' through DIALOG ended at 13:24:45 on the 28th of January 1987. For 0.417 hours of access time the charge was 29.19 dollars. The separate charge due to TELENET was 4.58 dollars. ?b 13 28jan87 13:24:45 User020257 29.19 0.417 Hrs File202 4.58 Telenet 33.77 Estimated cost this file 34.87 Estimated total session cost 0.444 Hrs.
[summary of features]The DIALOG system supports searches of many kinds. Various fields, such as date, author, and title, have been predefined, and a searcher can request documents which satisfy some condition on a particular field. Every document is indexed not only by every word in the document, but if index terms have been assigned to a document, then the document can be found via those index terms as well. Word frequency indexing or retrieval techniques are not, however, supported by DIALOG.
[humans not needed]For string-search and word-frequency systems humans are no longer needed to index documents. The computer does the work. What kinds of systems exploit these methodologies and don't get overwhelmed by the computational costs?
[cost]The computational feasibility of `pure' string-search is limited to small textual databases on conventional computers. The cost in computer time of searching character-by-character across the text database is high. Commercial systems do, however, offer a partial string search capability. Users may find documents containing any particular word but not necessarily any string.
[string search on small set]To do string-search the computer must load into its memory the document content before the search is performed. For a large system like MEDLARS one may be advised to do a retrieval through the word index. If one gets no more than about 300 documents in return, then one may do string-search on those 300 documents. In other words, string-search is best reserved for a small document set.
[parallelism]The decreasing cost of processors is stimulating the search for efficient uses of parallel computers. Work on very-large, textual databases is turning to parallel machines to deal with the need for reasonable response times when string searches are performed. The Connection Machine is commercially used for parallel string searching [Stan86]. The machine has 65,536 processors ($2 sup 16$). When scanning thousands of articles for a single string, a conventional machine would go through them one by one. The Connection Machine can read all of the articles at once, because each article, in effect, is assigned to an individual processor, with each processor executing the same `scan' instruction. The process can be metaphorically described as follows: "Each of 65,000 people in a stadium has a different document. A word is announced over the public address system, and everyone scans his article to see whether it contains that word." This approach makes `pure' string search computationally feasible.
[methods]Many word-frequency based document retrieval systems have been built in academia and extensively tested. One of the most famous is the SMART macrotext system developed by Gerard Salton's group at Cornell University [Salt83]. The system supports automated indexing, clustered documents, and interactive search procedures. Documents are basically represented as vectors of weighted words, and retrieval relies on similarity between document vectors and query vectors. indexing search
[STAIRS ranking]The STAIRS macrotext system supports ranking by word frequency. From a retrieved set of documents, a user can request a ranking based on word frequency. For instance, the user may specify that the more frequent a word in a document the more relevant that document is. This ranking facility is, however, invoked only after other search strategies have yielded a small document set.
[Personal Librarian]The macrotext system Personal Librarian supports word-frequency indexing and retrieval. Given a query of terms, the system can rank the relevance of documents to a query according to four principles: If one search term occurs rarely and another occurs commonly, documents with the rare term are considered more relevant than documents with the common term. The larger the number of different search terms occurring in a document, the more relevant the document will be. The higher the frequency of a given search term in a document, the more relevant the document will be. The fewer the number of words between occurrences of terms in a document, the more relevant the document will be. Queries can be posed as natural language and the system will extract search terms from the query. The user can specify a topic search in three ways: expanding a term (eg, expand computer) returns terms statistically related to the first term (see Exercise "Network"). expanding a document (eg, expand document34) returns terms statistically related to the document. matching a document (eg, match document34) returns statistically related documents. Personal Librarian works on personal computers or mainframes and various operating systems. The personal computer version operates with a windowing system that facilitates use by novices.
[printed indices]While some document retrieval systems offer word-frequency tools, these are not commonly used, partly because organizations which maintain document databases often want to produce printed indices. To properly structure printed indices, human indexing of the documents has been seen as critical. Once this human indexing has been done, it also supports computer retrieval.
[standards needed]When an individual has a small library, he develops an indexing language which may be highly idiosyncratic. For instance, material of recent interest may be in a stack on the table; one file drawer may hold proposals sorted by topic; and one bookshelf may hold books of a certain size. As the number of people who use a library grows, the need for standard indexing languages grows. Many types of indexing language exist; one unusual type is based on `keyword in context' principles.
[PRECIS]One method of automatically generating a simple kind of index for a set of documents is to list each word followed by a few of the words that occur in that word's immediate context. Such an index is called a key-word-in-context (KWIC) index. A substantial extension of the KWIC approach has been taken in the Preserved Context Index System (PRECIS)the name conveys the idea of context dependency as well as the fact that a precis of the subject is provided.
[relations among index terms]To index with the PRECIS method, an indexer scans a document looking for those terms which he regards as essential to a verbal expression of the document's subject content. He next considers the role which each of these terms plays in the subject as a whole. The relation between terms in the classification of the document is restricted to a handful of relations, including: [Aust84] 0) Key system, 1) Active concept, and 3) Study region. If one were indexing a document about `The management of railways in France', one would begin by breaking the subject into `management', `railways', and `France'. One then checks each of these terms against the set of relationships and decides under what relations to place each of the three terms. In this example `management' is recognized as the active concept. `Railways' would be stored under key system, and `France' would be under `study region'.
[published index]The published version of the indexing shows an entry for each term of the index. The indexing of `The management of railways in France', might appear as in Figure "PRECIS Published Index", with each term associated with all the other terms in the index in a systematic way. railways, management, France management, railways, France France, management, railways

[implementation]PRECIS is used by parts of the British Library for the classification of books. It was designed with the computer in mind but is largely a manual system both for indexing and retrieval. The British Library publishes the results of the PRECIS indexing in a document which is then used by searchers. A number of other PRECIS-like systems have been implemented [Farr77].
[evaluation]Retrieval has been compared for documents indexed with the Library of Congress Subject Headings (LCSH) and for documents indexed with the British Library's PRECIS scheme [Scha82]. Queries were about social science topics and about pure science. The users seemed equally satisfied with LCSH and PRECIS for queries in the pure sciences but felt that PRECIS allowed substantially more good documents to be retrieved in the social sciences than did LCSH. The explanation for the difference between the social and pure sciences may rest on the `soft' versus `hard' nature, respectively, of the vocabularies. In the social sciences, more so than in the pure sciences, terms tend to be used less precisely, new terms keep emerging, and several terms often overlap in meaning.
[thesauri are common]Thesauri are common in both specialized and general macrotext systems. The phone book illustrates a simple index which is meant to be understandable to all. A medical thesaurus shows the great detail which has evolved over time for a medical community.
[thesauri are common definition and example entry] The Yellow Pages is a phone directory which provides product and service information to an enormous audience. An Electronic Yellow Pages (EYP) has the ability to provide many additional features that a paper Yellow Pages can not. Each entry in the EYP can be viewed as a small document which may include pictures of products, photos of salesman, sentences describing the product, addresses, hours of operation, and maps. To properly convert the Yellow Pages into macrotext an augmented indexing scheme is needed (see Exercise "Yellow Pages").
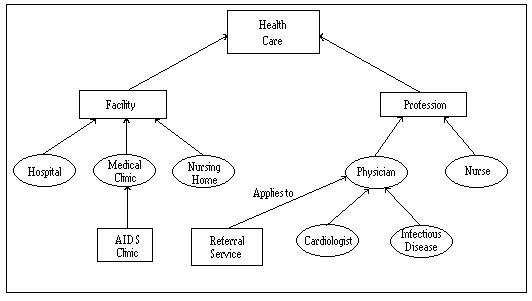
[indexing]Yellow Pages tend to have short indices. The directory for a city of millions of people may have an index of only a few pages. This index is usually presented as an alphabetically-sorted list of terms. Occasionally one level of indentation is employed; for example, a small part of an actual Yellow Pages index shows one level of indentation for types of physician (see Figure "Yellow Pages Index"). The popular advertising slogan `Let Your Fingers Do the Walking Through the Yellow Pages' implies that the user knows the routes which the walk should follow, but the only map is the skimpy index. Hospitals Medical Clinics Nurses Nursing Homes Physicians Cardiologists Infectious Disease Experts

[extended index language]An extended indexing language for the Yellow Pages would have several more levels than the current indexing languages for Yellow Pages. For paper, a small index is in some ways more manageable than a large index. For an electronic index, the index size is less a factor than is its organization and presentation. Figure "Electronic Yellow Pages Index" illustrates an augmentation of the index in Figure "Yellow Pages Index". New levels have been introduced into the hierarchy; now a user can find the concept `Health Care' and proceed from there to a breakdown of concepts into `Facility' and `Profession'. These three new terms also introduce two new levels in the hierarchy. `AIDS Clinic' has been added as a new leaf in the tree. Figure "Electronic Yellow Pages Index" also illustrates another augmentation which could be made to the index. Non-hierarchical relations might be useful. For instance, a `referral service' to direct patients to appropriate physicians would be important for some users of the Yellow Pages. `Referral service' could be explicitly connected to the term `physicians' via the non-hierarchical link `applies-to'.
[trends with MEDLARS]The MEDLARS bibliographic citation system at the National Library of Medicine uses thesaurus terms in representing queries and documents. Originally, retrieval was performed by a librarian in interaction with a user [McCa80]. Now simple interfaces and compact disks have allowed end-users to frequently, directly access the MEDLARS databases.
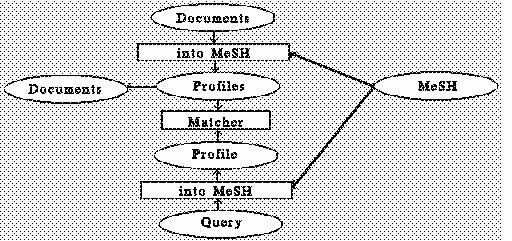
[flowchart]A flowchart of the MEDLARS system emphasizes that documents and queries are encoded into terms from a medical thesaurus (see Figure "MEDLARS"). A trained indexer scans a journal article and assigns it indexing terms from the Medical Subject Headings (MeSH). Searchers generate queries as Boolean combinations of terms from MeSH and are then shown the citations which were indexed with those terms.
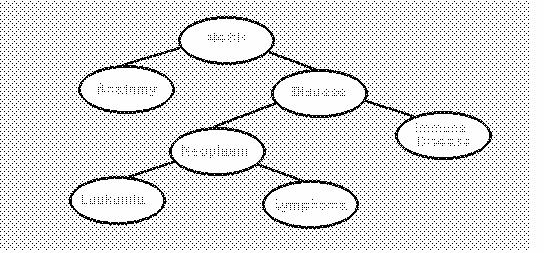
[deep hierarchy]MeSH includes about 100,000 terms in an 11-level hierarchy. A handful of terms are immediate descendants of the root node and include `Anatomy', `Disease', and `Chemicals'. The major classes of disease, such as `Neoplasm' and `Immune disease', are the immediate descendants of the `Disease' term. (see Figure "MeSH Tree").
[MeSH database structure]MeSH is so large that it needs its own sophisticated database structure. The record for a term in MeSH includes fields for `Online Note', `MeSH Tree Numbers', `Backward Cross References', and `MED66 Postings' [Sect86]. For the MeSH term `Ego' the `Online Note' says that `Ego' is synonymous with `Self', and the `MeSH Tree Numbers' field says that `Ego' occurs in the hierarchy at F1.752.747.189 and F2.739.794.206. One knows that `Ego' is non-hierarchically related to `Reality Testing' since it occurs in the `Backward Cross-References' field. From the `MED66 Postings' field one can recognize that `Ego' was used 618 times to index documents on MEDLARS prior to 1966.
[MeSH for medical students]At Harvard Medical School the students are introduced to an educational method that uses tutoring, self-pacing, and computers. Each student is provided with a personal workstation that facilitates communication with other students, with faculty, and with databases. The students are expected to take advantage of the computer to help themselves organize their classroom information. MeSH is being explored as a tool to help in the organization of information. Students may explore the MeSH vocabulary by browsing its hierarchical structure, and terms have been added to MeSH to make it more useful to students who want to learn about medical care and to organize their own library.
[selecting query terms with the mouse]One retrieval system is designed principally to help a novice user with a graphical display of a thesaurus [McMa89]. The user can move about the hierarchy by pointing and clicking with the mouse. Queries using thesaurus terms can be formulated by pointing to terms. Documents can be retrieved by the query, and the quality of the match between the query and the documents is also displayed graphically. The process of query formulation and document retrieval can be repeated often, and the system supports the comparison of the results of one retrieval against the results of the preceding retrieval.
[document ranking]Multiple windows are implemented so that the user can see simultaneously the thesaurus, a histogram of document rankings, and the document descriptions themselves. The ranking of documents produced by the system is presented graphically in a histogram. From the rankings one can go via the mouse to each document.
[satisfaction depended on user background]A survey of users of this system and a more traditional system revealed that the user background was a critical factor in determining the user satisfaction. The lack of experience of the users with mouse-driven interfaces interfered with their appreciation of the graphical, multi-window system, but they agreed that the graphical concept should be a better way to handle an information retrieval interface.
[historical_example]Microtext is linked text within a single document. Macrotext, on the other hand, is large collection of documents with links among the documents. A microtext system is used by one person on a personal computer, while a macrotext system typically runs on a large computer and is accessed by many people. In many situations this distinction between microtext and macrotext may be difficult to apply. For instance, thousands of notecards with text about the shipping activities in the Liverpool harbor during the 18th century are being organized in the Liverpool University Archives. Is this microtext or macrotext? The cards are being indexed for retrieval as one would expect of macrotext. On the other hand, the cards are also being connected in a way that would support browsing and microtext. Ultimately, many systems will probably combine microtext and macrotext features. The user will be able to search the document database and upon finding interesting material may start browsing.
[motivation]When a searcher finds a citation through a macrotext system, their next likely requirement is the entire cited document. If this is available online, then the user would want facilities for browsing or reading the document. This browsing and reading functionality are the strengths of microtext, and systems are being marketed which combine the strengths of microtext and macrotext in what might be called `large-volume microtext'.
[full text]Since many documents are currently prepared on the computer, at least, the alphanumeric parts are easily made available. Some database vendors now provide online the alphanumeric full-text of major journals [Hump86]. Subscribers to such a database service may see the latest copy of the text of the journal online, before they get the paper copy in the mail. Encyclopedias, dictionaries, and textbooks are also increasingly available as full-text online.
[videodisc for storing exact image]Furthermore, the availability of large amounts of cheap storage in the form of optical discs or videodiscs is supporting the delivery of online documents with images. Photographs of journals from cover-to-cover can be economically stored on videodisc. In this way over 200 journals are distributed in the ADONIS system [Camp87]. The videodisc is indexed by typical bibliographic citation information, and a user of ADONIS can request an exact copy of a document as photographs of every page.
[development history]In experiments in the mid-1980s a document retrieval system was combined with the Guide microtext system to create a new type of macrotext. The microtext interface was augmented to allow options to generate Boolean queries [Bove87]. Pointers to retrieved documents were given in one window, and queries were developed in another window. Within the retrieved window the user could explore further details of each document by using microtext buttons to `unfold' a document. The method of browsing an individual document involved the same interface as that for generating queries.
[applications]Now the commercial version of Guide has evolved and extensions of it for large volume work have been implemented for such diverse applications as: manuals for automotive repair and catalogs of spare automotive parts, standards documents for design engineering in the aviation industry, user documentation for a computer manufacturer, and maintenance manuals for power generation facilities. These applications may easily require more than a gigabyte of memory and include thousands of complete documents. The new system, called IDEX, allows users to search large document databases and to browse individual documents [Ritc89].
[catalogue cards]The large-volume component of IDEX uses a catalog card to represent the indexing of a document and supports a query language. Each document is represented by a catalog card that includes Document Type, Date, Author, and Keywords. The indexer can also determine that some documents will be accessible to certain users and not others and can elect to organize certain terms as a hierarchy. The hierarchies are then included on special catalog cards which searchers can exploit to find documents.
[converting between text and hypertext]IDEX can automatically convert text to microtext or microtext to text. Given that a document has been prepared with a standard markup language, the system can automatically translate the document into a Guide form which users can browse. Furthermore, the system can print a document by traversing the Guide hierarchical representation in a depth-first fashion and printing the sections as it visits them. The user can request to have a paper copy or a screen copy.
[combining micro and macro]What is particularly intriguing about IDEX is that once a text has been converted into microtext, it also becomes integrated into macrotext. IDEX maintains a document database which can be searchedthus forming macrotext. Once a pointer to a document is found, the document can be browsed in detailthe browse facility indicates microtext. This integration of microtext and macrotext exemplifies the spirit of hypertext.
[advantages of electronic form]When a large reference book is to be browsed with microtext techniques, the question may arise as to where the reader should start. The reader may have some specific topic in mind and want to browse only in the areas closely connected with that topic. Research with SuperBook has shown that a macrotext search facility can significantly help users to get information from a book. Some users were given a paper copy of the book and asked to answer a set of questions, while other users were given the book in SuperBook (electronic) form and asked to answer the same questions. The SuperBook users answered more questions correctly and took less time than did the users of the paper copy [Egan89].
[first search, then browse]Word-frequency approaches can be used to automatically index the paragraphs of a reference book. Then the reader can generate search statements as he might with a regular macrotext system and be given relevant paragraphs. Once the searcher has retrieved a relevant paragraph, then he may follow the microtext links from that paragraph in browsing.
[intrinsic and extrinsic weights]If a hierarchically-structured hypertext contains several blocks of text with the term x, in response to a query for x the system could emphasize the blocks whose children in the hierarchy also contain term x. The utility of a block of text relative to a query can be approximated by a numeric weight consisting of two components. The intrinsic component is computed from the number and identity of the query terms contained within the block. The extrinsic component is computed from the weight of immediate descendants. The optimal starting point for browsing is the block with the highest weight, and this block is found through a macrotext search technique.
[application to medical reference book]For a hypertext medical reference book, word-frequency techniques were used to connect terms to blocks of text [Fris88]. The reference book was first converted into a microtext by exploiting the markup language of the handbook. Then word-frequency indexing techniques were combined with information about the microtext structure to facilitate initial entry into the text via a query (see Exercise "Searching for Paragraphs").
[dream of connectivity]One of the dreams of hypertext users is to easily connect documents. Vannevar Bush had said that the user would be able to find documents which otherwise would be lost [Bush45]. Some have spoken of the universe of connected documents. Behind these dreams is a dilemma. If the connections between documents are idiosyncratic and thus intuitively clear to one individual, then those same connections may be unclear to another individual. The links and nodes of hypertext constitute a language. Different hypertexts have different languages. To connect the languages is to connect the hypertexts.
[recent history of institutional commitment]In the 1960's, a connection between the Universal Decimal Classification and other classification systems was established [Dahl83]. The United Nations has funded the construction of unified languages for the classification of documents in a number of fields, including in particular the social sciences. In 1977, the United Nations undertook the ambitious project of collecting, identifying, clarifying, representing, and delivering data on concepts in the social sciences on an international level. During the course of the project, they discovered the need to define clearer criteria for identifying the concepts and for preparing operative definitions. The Armed Services Technical Information Agency and the Atomic Energy Commission have each linked their indexing languages, [Sven83] while the National Library of Medicine has developed the Unified Medical Language System which connects many of the indexing languages of biomedicine.
[goals]Translation schemes that take a meta-language or indexing language from one group and make it compatible with a meta-language from another group have been devised.. The problem is to formulate translation schemes that preserve the original meaning as much as possible, while allowing different groups to create or change their languages with as much autonomy as possible. The objectives include maximizing expressive adequacy, minimizing the need for consensus, and minimizing the need for propagation of changes.
[translation schemes]A common language for a set of groups is the language that all the groups use to communicate with one another. So to communicate using the common language, each group must either use the common language itself or be able to translate between the common language and the group language (see Exercise "Translations"). For the case where all the group languages have the same relationship to the common language, then general solutions to the translation problem include: no common language, identical group language, external common language, and internal common language (see Figure "Group versus Common Language").
[empty common language]When no common language is shared by groups that wish to communicate, each pair of groups must be able to have pairwise translations made into and out of each other's languages. This corresponds to the real-world situation with languages like English, French, and Japanese. Such a scheme can provide case-specific translations in fine-grained detail. The scheme also supports autonomous evolution. It is, however, only applicable when the effort to build the translation rules and dictionaries can be justified.
[identical group language]When the common language is the same as all group languages, the need for consensus is large. Since all groups have to agree on changes, the only changes that are easy for a group to make will be those that do not affect other groups or those that are valuable to all groups. The Dewey Decimal Classification Scheme is such a common language or standard and is used in the classification of books in libraries. Classification Scheme
[external common language]With an external common language, a group communicates with another by first translating its language into the common language, and then having the receiving group translate the common language into its own group language. This approach is applicable when groups have well-established group languages and can't afford pairwise translations with all other group languages. Languages like Esperanto were designed to serve as external common languages.
[internal common language]The internal common language approach has special appeal when each group language is a hierarchy. If, for instance, the common language is the root and top levels of the hierarchy, then when highly specific, idiosyncratic terms from one group language need to be translated into the common language, the translation procedure need simply move up the hierarchy until the common term is reached. This scheme is useful when there do not already exist numerous well-established and incompatible language groups, there are important commonalities across groups, and there are also significant local variations among groups.
[translate by mapping]One way to begin translating from one meta-language to another is to map the terms of one meta-language to the terms in the other meta-language. How can this mapping be done? How far can one get with direct lexical matching of terms? What role might knowledge about the components of terms play?
[syntactic match]A variety of rearrangements of terms can be performed to determine whether a kind of syntactic match exists between two terms [Nieh85]. Two examples illustrate the type of rewriting that can facilitate connecting two main terms: [Klin85] x of y $==$ y x (as in shortness of breath $==$ breath shortness) x, y $==$ y x (as in cancer, lung $==$ lung cancer). Here `u $==$ v' means that u is the nearest concept for v.
[word decomposition]After decomposing two terms into their components, one can match the terms based on these components. Such matching may succeed where direct matching fails. For instance, start with the two terms `hypertension' and `high pressure'. If the term `hypertension' has been decomposed into the components `hyper' and `tension' and those components have been equated with `high' and `pressure', then `hypertension' would map to `high pressure' [Wing86].
[synonyms]The synonym relation can assist in mapping. Assume that one language includes a term called x which has a synonymous term called y. The other language includes a term called z which has a synonymous term called y. By going through the synonymous term y, an algorithm can connect x and z [Soer74].
[Vocabulary Switching System]The Vocabulary Switching System (VSS) contains the subject descriptors from 15 indexing languages in the areas of physical science, life science, social science, and business. With it, a user is able to generate automatically document requests in 15 indexing languages based on a request in just one [Nieh85]. VSS utilizes five file types: term file, word file, stem file, stem phrase file, and concept file. The first four are inverted files, and these provide access to the fifth file. The term file contains all terms in all indexing languages. Each term is assigned a pointer to a concept, which is used to retrieve data from the concept file. The word file contains a record for each component word in the term file. This file is useful for retrieval of parts of multi-word phrases. The stem file, like the term file, contains an inverted list of all terms. However, each term is processed by a stemming algorithm to create a root or stem. User input is stemmed via an identical algorithm when a stem search is specified. The stem phrase file contains stem strings, formed by the stem of each of the unique words in a term. This file is useful for retrieving terms in which the user query differs from the term only in word endings. VSS has been shown to reduce search preparation time, improve search strategies and retrieval, and increase usage of existing databases.
[mapping and nearest]The indexing languages of hypertext may be viewed as semantic nets. Connecting two semantic nets allows access directly or indirectly to the contents of two semantic nets or the documents to which the semantic nets point while only requiring mastery of one semantic net. Methods for connecting two semantic nets may depend on mapping or on merging. Assume that the semantic net includes relations of the following types: synonymous, broader, narrower, and related. In mapping two semantic nets $SN sub 1$ and $SN sub 2$ a new slot has to be entered for each concept in $SN sub 1$ which slot can be called the nearest slot. In merging $SN sub 1$ with $SN sub 2$ the nearest slot is not needed but changes may be made to the values for the synonym, broader, narrower, and related slots for all concepts.
[objectives like database management systems]While database management systems often deal with numbers, such as salaries, and hypertext systems deal with text, each system has common objectives. Three primary objectives of database management systems are: making an integrated collection of data available to a wide variety of users; providing for quality and integrity of the data; and allowing centralized control of data. These goals can be related to the goals and problems of merging languages: the objective of merging languages which index documents is to make data available to a wide number of users; one of the difficulties in this merge is to resolve the conflicts which can occur when two different systems disagree on the relationship which should exist between two terms; the merged languages can be controlled from a centralized site. As database work becomes more complex, more sophisticated methods for ensuring integrity and maintaining central control are needed. For instance, in the modeling of time in databases it becomes important to decide when two versions of data from different times are equivalent. This problem is connected to that of determining when two concepts in different languages are equivalent.
[theory]One can prove that retrieval through two merged semantic nets may lead to better information retrieval than retrieval through each semantic net separately [Mazu86]. Given that: semantic net A has the term $a sub 1$ with children $a sub 2$ and $a sub 3$, semantic net B has the term $b sub 1$ with children $b sub 2$ and $b sub 3$, a search on $a sub 1$ in the document space indexed by semantic net A retrieves all documents that contain the terms $a sub 1 ,~ a sub 2 ,~ or~ a sub 3$, a search on $b sub 1$ in the document space indexed by semantic net B retrieves all documents that contain the terms $b sub 1 ,~ b sub 2 ,~ or~ b sub 3$, $a sub 2~ =~ b sub 1$ and a merge of semantic net A and semantic net B reproduces semantic net A but adds $b sub 2$ and $b sub 3$ as children of $a sub 2$ (see Figure "Merging Semantic Nets"). Then: a search on $a sub 1$ in the document space indexed by semantic net A after the merging of semantic nets A and B retrieves all documents that contain the terms $a sub 1 ,~ a sub 2 ,~ a sub 3 ,~ b sub 2 ,~ or~ b sub 3$. Since more relevant documents should be retrieved with the search { $a sub 1 ,~ a sub 2 ,~ a sub 3 ,~ b sub 2 ,~ b sub 3$ } than with the search { $a sub 1 ,~ a sub 2 ,~ a sub 3$ }, the merge of semantic nets A and B has improved retrieval. A retrieval that knew $a sub 2$ equaled $b sub 1$, but didn't know that $b sub 2$ and $b sub 3$ were more specific than $a sub 2$ would miss relevant documents. Thus a merge of two semantic nets may lead to a more powerful semantic net for information retrieval purposes.
[similarities and differences]The process of merging semantic nets involves two crucial steps: finding similarities and exploiting differences. Finding similarities involves steps like those in mapping. Terms in $SN sub 1$ are mapped to terms in $SN sub 2$. Exploiting differences can involve a number of principles, but two which are most germane could be called hierarchical transitivity and analogy. Merging by hierarchical transitivities involves grafting a subtree from one semantic net into another semantic net. Merging by analogy involves determining that terms are related in one thesaurus but not in the other and then copying the relationship into the semantic net that was lacking it. For a merging by analogy example, if in $SN sub 1$ concept `a' has a relationship to concept `b' but the same concepts in $SN sub 2$ have no direct connection, then $SN sub 2$ can be augmented by copying the relation between concepts `a' and `b' from $SN sub 1$ into $SN sub 2$.
[conflict resolution]One merge played a key role in the construction of a semantic net for the field of medical information science [Mili88]. However, various conflict resolution strategies had to be introduced when the information in one semantic net was not consistent with that in the other semantic net (see Exercise "Inconsistency"). For instance, in one semantic net `pattern recognition' was broader-than `artificial intelligence', while in the other semantic net `artificial intelligence' was broader-than `pattern recognition'.
[history of technology]In the 1950s, there were significant advances in the theory of indexing documents, and the use of Boolean expressions to indicate index term relationships was elaborated. Also in the 1950s precision and recall were defined as criteria of retrieval effectiveness. In the early 1960s the first large-scale macrotext system, MEDLARS, became available with documents being manually indexed into terms from an index language. In the 1970s methods of classifying documents by word-frequency were established. Many current macrotext systems maintain indices of all the words in the document collection. Queries are posed as words which are matched against words in documents. One ironic feature of this history is that, while the technology has advanced, the conceptual sophistication of the indexing and retrieval strategy hasn't. What has gone forward with the technology is the amount of literature that can be stored and accessed.
[macrotext system advantages]The speed of the computer, its ability to store vast amounts of information, and its ability to manipulate information all contribute to the special features of computerized macrotext. A computer macrotext system offers many advantages over a paper system: The search is faster. Queries can be readily reformulated and a new search executed. From any one place more literature is available online than on paper. More access points exist for each document. One way to search in a macrotext system is to specify an item, like an author name, after which a list of citations which contain that item are returned. Alternatively, one can search by content labels or a combination of content labels and author names. Many other types of queries can be generated and each should be able to operate on large document sets quickly.
[strings and words]The methods for retrieving documents which exploit the simplest patterns are the string and word-frequency methods. In the string method, documents are found by locating strings of characters in the documents. In the word-frequency method, patterns of co-occurrence of words support indexing and retrieval.
[word patterns in microtext and macrotext]Word-frequency tools can generate characterizations of blocks of text, which on the one end might be large documents and at the other end might be short paragraphs. With queries that perform matching based on word-frequency one could thus get not only a pointer to a document within a large set of documents but also continue the search to locate smaller text blocks within a single document. Within one large document, the paragraphs may be considered mini-documents to which macrotext methods may be applicable. Macrotext methods facilitate searching and users may want to do searching to put themselves in a neighborhood from which reading or browsing may proceed. Macrotext differs from microtext in that its emphasis is on searching, in contrast to microtext, which emphasizes browsing. Together, macrotext and microtext form a foundation for hypertext.
[indexing language]A thesaurus or indexing language assists indexers and searchers in the choice of appropriate terms and facilitates inclusive searches. If term x has y as a narrower term, then an inclusive search with x automatically includes y. But the theory and practice of indexing languages needs to be further elaborated. The structure of current indexing languages is often idiosyncratic. The better languages show regular patterns. As the structure becomes more regular, the opportunity to exploit that structure for indexing and retrieval improves.
[indexing language versus outine]Indexing languages constitute a semantic net which is usually hierarchical. The question remains as to what relationship should exist between indexing languages and outlines for individual documents. An outline may also be viewed as a semantic net. Typically, indexing languages resemble taxonomies and have information like `bacteria are microorganisms are organisms'. The outline of a typical scientific paper is `1. Introduction', `2. Method', `3. Result', and `4. Discussion', but the outline of a large textbook may be more taxonomic in character (see, for instance, the outline of this book). Creators and accessors of hypertext should be able to connect the semantic nets of macrotext and microtext (indexing languages and outlines, respectively). The insights about search interfaces, including giving users alphabetical and hierarchical views of the indexing language, should also apply to the outlines of microtext.
[connecting indexing languages]A dominant problem in macrotext systems is connecting across document systems which use different indexing languages. The same problem exists at the microtext level, in that a document by one author may well have a semantic net which has nothing in common with the semantic net by another author for a document which is otherwise similar. The hypertext system should facilitate the connections among these semantic nets. One simple way is to map the terms from one semantic net into those of another and merge the semantic nets at those points of commonality.
[set and logical operators in queries]Exercise "Set and Logical Operators in Queries": In document systems the representations for documents and queries usually simplify the document or query. A document might be characterized by a set of words, and queries might be words connected by the set operators intersection , union , and complement . Imagine three documents indexed, respectively, as {boy, dog}, {dog, football}, and {boy, football}. Give examples of queries and the documents which they should retrieve. How do these set operators relate to Boolean logic operations? (30 minutes).
[word frequency]Exercise "Word Frequency": Develop an algorithm which will identify the terms in a document whose frequency makes them significant. (45 minutes).
[a relevance formula]Exercise "A Relevance Formula": Assume that a document is represented as a weighted vector of m terms ($ doc sub 1 , ... , doc sub m$) and that queries are similarly represented as ($ qu sub 1 , ... , qu sub m$), where $doc sub k$ refers to the weight on the kth term of the vector for this document and $qu sub k$ has the corresponding meaning for the query. Define a measure of relevance between the document and query. (25 minutes) discrimination analysis
Exercise "Discrimination Analysis": Given a set of n document vectors over a vocabulary of k terms, the vector for $document sub j$ may be of the form ($w sub 1,j , w sub 2,j , . . . , w sub k,j$), where $w sub i,j$ is the weight of $term sub i$ for $document sub j$. A centroid C of the set of document vectors may be defined with its ith term $c sub i$ defined as follows: How might the centroid be used in assigning weights to terms so that the vectors are best separated? (30 minutes). hierarchy search benefit
Exercise "Hierarchy Search Benefit": If one is searching for documents, a hierarchical organization can reduce the cost of search. Present an analysis of the search cost in a hierarchy as contrasted to the search cost when no organization exists. The advantage is similar to that of ordering a list in order to reduce the cost of search on the list. (30 minutes assumes background in analysis of algorithms). publish
Exercise "Publish": To test the hypothesis that the `more important a journal, the more frequently its authors publish' both the notion of importance for a journal and of author publication frequency need to be defined. Suggest such definitions. Go to the library or a macrotext system and collect information to test the hypothesis. (2 hours).
[validity of indexing]Exercise "Validity of Indexing": How does the performance of an average indexer compare to that of an expert indexer? The evaluation should consider that some index terms may be close to the expert's choice but not correct. Suggest a method for evaluating indexing that exploits the relationships in the thesaurus from which the indexing terms are chosen. (45 minutes).
[network]Exercise "Network": Develop an algorithm which will take as input a set of documents, each of which has been indexed into a set of terms, and output a network of index terms. A term-document matrix may be imagined in which a yes entry in the $term sub i , document sub j$ cell of the matrix means that $term sub i$ was used in the indexing of $document sub j$. Two terms have the same distribution across documents, if they are used in indexing exactly the same documents. If two terms have similar distributions across the documents, then those two terms should be connected in the graph. While complex definitions of similarity have been produced, [Mili85] a simple one is good enough for this exercise. Define a simple measure of similarity and build a small network of terms by connecting terms that have similar distributions across a few short documents. (2 hours).
[Yellow Pages]Exercise "Yellow Pages": Why should someone want an Electronic Yellow Pages when a paper Yellow Pages is free, is delivered to the door, and is adequate for many needs? How big should an index be in order to be most useful on paper versus computer? (30 minutes).
[searching for paragraphs]Exercise "Searching for Paragraphs": To search for a block of text from which browsing may ensue, an intrinsic block weight may be useful which satisfies the following conditions. The intrinsic block weight is proportional to the number of times each query term occurs in the block and inversely proportional to the number of blocks that contain each query term. A block with many immediate descendants, but only one query term in an immediate descendant, has a lower extrinsic block weight than does a block with fewer immediate descendants but also one query term on one immediate descendant. Suggest a formula for the intrinsic block weight of block i due to term j. The intrinsic block weight component may be combined with the extrinsic component due to weights of immediate descendants, to determine the total weight for $block sub i$. Also suggest a formula for the total weight for $block sub i$. (45 minutes). translations
Exercise "Translations": Group languages and common languages may be related in several ways, such as: no common language, identical group language, external common language, and internal common language. What are two other relationships between common and group language? (25 minutes).
[inconsistency]Exercise "Inconsistency": Merging two medical semantic nets illustrates the role of consistency (see Figure "Inconsistency in Merge"). In one `arm injury' is broader-than `hand injury'. In the other `arm injury' and `hand injury' are both narrower-than the same concept. How might one resolve this inconsistency? Might any secondary problems ensue? (45 minutes).