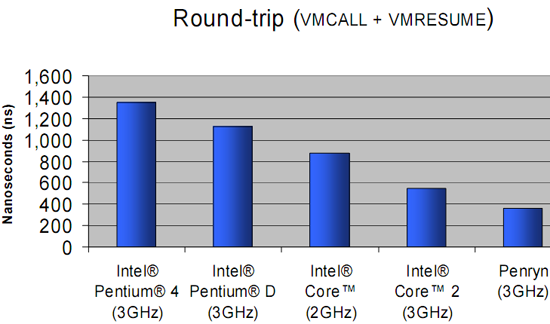
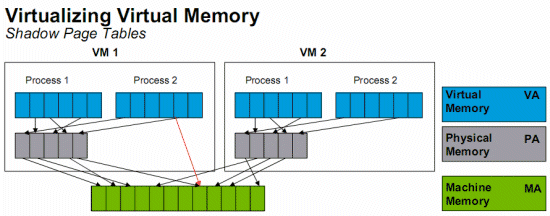
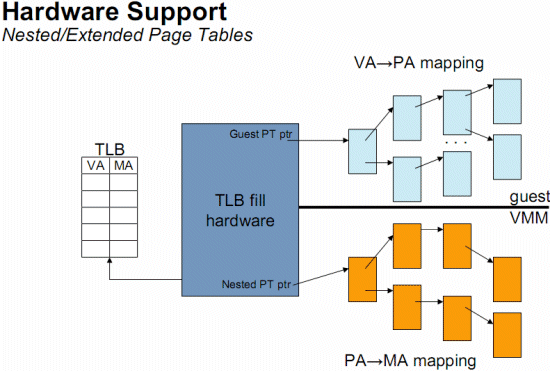
The Benchmarks
Performance is somewhat a less popular subject among the
virtualization evangelists and little detail is provided
in the glossy brochures. A superficial look at most of
the published benchmarks seems to justify this lack of
interest: who's worried about a 3% to 10% performance
loss with the current powerful quad-core CPUs? Indeed,
hypervisor or VMM based virtualization - ESX, Xen -
perform quite well, especially if you compare it with a
typical host-based solution such as VMware server and
Microsoft Virtual Server 2005. The latter run their
virtualization layer on top of a host OS, which results
in rather low performance.
Look at the graph[6] below. It shows the
benchmarks performed by the university of Cambridge. The
benchmark compares the native Linux performance (L) with
the Xen performance (X) and with VMware Workstation (V)
and User Mode Linux. The latter are based on host OS
virtualization: the virtualization layer runs on top of
a host OS.
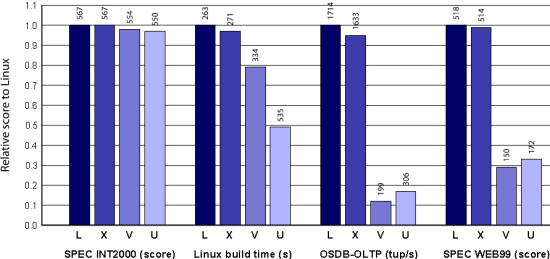 Virtualization on top of host OS is a bad idea
for many typical business applications.
Virtualization on top of host OS is a bad idea
for many typical business applications.
The
most quoted benchmark by the
virtualization vendors is SPEC CPU 2000 integer. As
you can see in those links, every kind of virtualization
technology scores very well. According to these numbers,
Xen performs just as well as native. However, once you
start a memory intensive benchmark such as a Linux
kernel compile, it is clear that the OS hosted
virtualization solutions cannot keep up. Throw in OLTP
and web applications and performance is simply abysmal.
There is a reason why SPEC CPU 2000 integer is quite
popular. It's a CPU intensive benchmark that rarely
accesses any other hardware, and it avoids using the OS
kernel much of the time. It is also quite remarkable
that the "2000" version is used. The 2006 version has a
larger memory footprint, which will probably cause a bit
more performance loss when virtualized.
Anyway, it is clear that SPEC CPU 2000 integer
numbers on virtualized machines prove very little. This
kind of software completely avoids the more challenging
code that a VMM has to deal with. What happens with
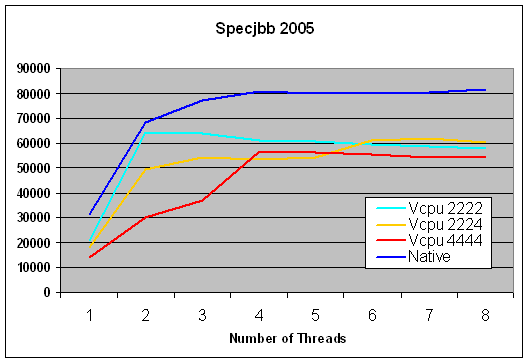
Specjbb2005? That server benchmark is also mentioned a
lot in the performance numbers of the virtualization
vendors. It's true that they show some results, but most
Specjbb2005 benchmarks are run one CPU, and if they are
run on more than one virtual CPU, only one VM is active.
That is of course not very realistic: you do not
virtualize your server to run only one VM.
We will keep our full benchmark report for the next
article, but let's take a quick look at some of the
benchmarks that we ran. We used our quad Xeon MP Intel
SR6850HW4 (4 x 3.2GHz dual-core Xeon 7130M,
Full configuration here) and ran Specjbb2005 the
same way
we configured it here. Hyper-Threading was disabled
to avoid inconsistencies in our benchmarks.
|
Virtualization Performance Testing |
| Number of VMs |
CPUs per VM |
SUSE SLES 10
Xen 3.0.3 |
VMware ESX
3.0.2 |
| 1 |
1 |
1% |
3% |
| 1 |
4 |
3% |
7% |
| 4 |
2 |
5% |
15% |
| 4 |
4 |
7% |
19% |
For our impatient readers: yes, there is a fully updated report with
the newest Xeons, Opterons, and hypervisors coming (ESX
3.5 etc.). We are well aware that these numbers do not
give you a decent picture of the virtualization
landscape, but they are not meant to be comprehensive.
They are nothing more than a teaser.
However, even these slightly outdated results are
very interesting. If you do not pay attention, a "one
CPU on one VM" benchmark tells you that virtualization
comes without any performance loss whatsoever. However,
a much more realistic setup is that you run four virtual
machines and you assign two virtual CPUs to each, as
there are eight CPU cores available. The performance
loss is not dramatic, but it is measurable now.
In the last line (four vCPUs per VM), we still used
exactly the same load as in the 2-2-2-2 configuration.
At the highest load, we only ran eight threads. The
performance loss was on average a bit higher, but the
table above is not telling the whole story. Look at the
graph below.
If you assign more virtual CPUs than you have, it is important to know
that the virtualized performance that you get at lower
loads can be a lot lower when you assign one virtual CPU
for each real CPU.
Don't get us wrong: the current virtualization
products offer very good performance in most cases.
Nevertheless, the impression that virtualization comes
without any significant performance loss in almost any
situation is not accurate either. For example, we have
noticed that even a simple OLTP sysbench load loses more
than 20% on a very powerful Xeon 5472 server. We have
even seen performance losses in 40% range in some cases.
It is too early to analyze this as the testing efforts
are still in progress, but we feel that more performance
research will yield some interesting results.