The remote procedure call (RPC) mechanism provides a service to the application programmer to allow transparent use of a server to provide some activity on behalf of the application. This can be effectively used to interact with a computational or database server, and has been used on some system to provide access to operating system services. The later use is found predominantly in micro-kernel based systems rather than the traditional monolithic kernels found in most UNIX systems, and is especially useful in distributed operating systems.
Remote procedure calls are expressed as ordinary procedure or function calls within the code that uses them. These calls do not require a special compiler for the program source code. The advantages of this include transparency: the RPC layer can be replaced with direct function calls if they become available and the distributed nature of the processing is not needed. Another major advantage (indeed, the driving advantage for the initial development of RPC) is the familiarity of the interface: most programmers are accustomed to some form of procedure call. This allows ready adaptation of the RPC mechanism into existing systems, with full understanding of applications being delayed.
What makes remote procedure calls different? The actual calls generated by the compiler are no different than any other calls that you define directly in your program. The real differences start once the procedure call is made.
Remote procedure calls are really just a way of hiding an underlying message passing protocol. (What form of interprocess communication isn't?) It provides a convenient way of allowing a high-level interpretation of system functionality to be used in programming at the application level, while abstracting the low-level communication mechanisms.
The best-advertised use of RPC mechanisms is to allow an application to make a simple function call to a well-defined interface. The RPC mechanisms provide a stub which translates any arguments to a flattened form which may be transmitted over a network to another system, where the arguments are unpacked by another stub in the server process and passed to the actual function or procedure being called. The return value of the procedure is passed back to the caller in a similar manner. While all this overhead has been incurred, the caller's has been blocked, and does not resume until the return has been received. A well-known application of RPC in this manner is the Network File System, implemented with Sun's ONC/RPC protocol.
Each call to an RPC function calls a stub function that doesn't actually implement the desired computation, but packs its arguments into a flattened (or marshalled) representation. This flattened form is then packed across a network to an RPC server where the arguments are unpacked and passed to the implementation of the function required. This incurs a moderate amount of overhead, but allows a much more flexible environment. The marshalling of the arguments can impose the most significant limits on the passing of complex data structures since many semantics and multiple-reference structures can be lost in automated translation.
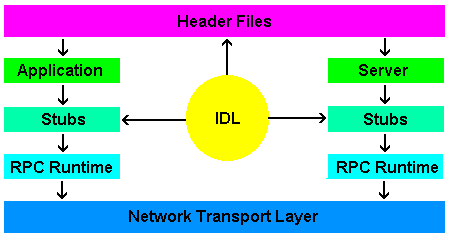
It is important to note that the stubs used at the client and server processes are generated automatically; the programmer need not define flattening and restructuring mechanisms for each function in the interface. This typically requires a large support library as part of the RPC system, but supports transparency and generality over the network.
The automatic generation of stubs for both the client and server sides of the
system is supported by an
This class of languages is designed for the cross-platform specification of function call interfaces, much as header files are written to define the interface to a module of C or C++ source code. An interface defined in this way describes the data types used by a set of function, the parameter types and sequence, and the return types. For programming languages which require some sort of header file or provide a foreign function interface (FFI), the definition language translator will provide any files which are needed to define the interface to the compiler or other development tools.
The diagram below illustrates the relationships between the various aspects of an RPC system.
Server side interface are usually called skeletons, not stubs.
Interesting work has been done to optimize performance through manipulation of the protocol stack to limit the overhead associated with transferring large data structures.
Systems have been developed which take advantage of the use of automated tools to create these interface definitions to incorporate a distributed object management system into an RPC-based application. This is done with the Object Managerment Group's Common Object Request Broker Architecture (CORBA) and Xerox PARC's Inter-Language Unification (ILU). The scope of these projects extend beyond RPC, and can rely on native RPC services of the underlying system.
Another use of RPC has been the provision of operating system services in separate ``domains,'' where each domain represents a distinct address space. This can be used to provide interfaces to such services as file systems, print spoolers, and even the network layer itself. In this application, where the client and server reside on the same hardware, significant performance savings can be achieved by avoiding network overhead.
This is our textbook. You should have a copy of this.
This is a good general reference book on traditional operating systems, and includes some information on RPC and distributed computing toward the end, but does not go into great detail on the topic. Dr. Henry uses this book to teach the undergraduate operating systems course here.
This last reference is poorly written and does not go into any real depth, but does provide a concise overview of several available protocols used in a variety of environments. Commercial protocols are included in addition to those developed in research-only environments. It also includes a good bibliography.