
Web Caching
By Duane WesselsJune 2001
1-56592-536-X, Order Number: 536X
318 pages, $39.95
| |
Web CachingBy Duane WesselsJune 2001 1-56592-536-X, Order Number: 536X 318 pages, $39.95 |
Chapter 5
Interception Proxying and CachingContents:
Overview
The IP Layer: Routing
The TCP Layer: Ports and Delivery
The Application Layer: HTTP
Debugging Interception
Issues
To Intercept or Not To InterceptBecause of problems such as these, interception caching has become very popular recently. The fundamental idea behind interception caching (or proxying) is to bring traffic to your cache without configuring clients. This is different from a technique such as WPAD (see "Web Proxy Auto-Discovery"), whereby clients automatically locate a nearby proxy cache. Rather, your clients initiate TCP connections directly to origin servers, and a router or switch on your network recognizes HTTP traffic and redirects it to your cache. Web caches require only minor modifications to process requests received in this manner.
As wonderful as this may sound, a number of issues surround interception caching. Interception caching breaks the rules of the Internet Protocol. Routers and switches are supposed to deliver IP packets to their intended destination. Diverting web traffic to a cache is similar to a postal service that opens your mail and reads it before deciding where to send it or whether it needs to be sent at all.[1] The phrase connection hijacking is often used to describe interception caching, as a reminder that it violates the Internet Protocol standards. Interception also leads to problems with HTTP. Clients may not send certain headers, such as &Cachectrl;, when they are unaware of the caching proxy.
In this chapter, we'll explore how interception caching works and the issues surrounding it. The technical discussion is broken into three sections, corresponding to different networking layers. We start near the bottom, with the IP layer. As packets traverse the network, a router or switch diverts HTTP packets to a nearby proxy cache. At the TCP layer, we'll see how the diverted packets are accepted, possibly modified, and then sent to the application. Finally, at the application layer, the cache uses some simple tricks to turn the original request into a proxy-HTTP request.
Overview
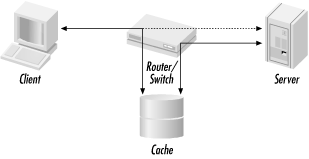
Figure 5-1. Interception proxying schematic diagram
Figure 5-1 shows a logical diagram of a typical interception proxy setup. A client opens a TCP connection to the origin server. As the packet travels from the client towards the server, it passes through a router or a switch. Normally, the TCP/IP packets for the connection are sent to the origin server, as shown by the dashed line. With interception proxying, however, the router/switch diverts the TCP/IP packets to the cache.
Two techniques are used to deliver the packet to the cache. If the router/switch and cache are on the same subnet, the packet is simply sent to the cache's layer two (i.e., Ethernet) address. If the devices are on different subnets, then the original IP packet gets encapsulated inside another packet that is then routed to the cache. Both of these techniques preserve the destination IP address in the original IP packet, which is necessary because the cache pretends to be the origin server.
The interception cache's TCP stack is configured to accept ''foreign'' packets. In other words, the cache pretends to be the origin server. When the cache sends packets back to the client, the source IP address is that of the origin server. This tricks the client into thinking it's connected to the origin server.
At this point, an interception cache operates much like a standard proxy cache, with one important difference. The client believes it is connected to the origin server rather than a proxy cache, so its HTTP request is a little different. Unfortunately, this difference is enough to cause some interoperability problems. We'll talk more about this in "Issues".
You might wonder how the router or switch decides which packets to divert. How does it know that a particular TCP/IP packet is for an HTTP request? Strictly speaking, nothing in a TCP/IP header identifies a packet as HTTP (or as any other application-layer protocol, for that matter). However, convention dictates that HTTP servers usually run on port 80. This is the best indicator of an HTTP request, so when the device encounters a TCP packet with a source or destination port equal to 80, it assumes that the packet is part of an HTTP session. Indeed, probably 99.99% of all traffic on port 80 is HTTP, but there is no guarantee. Some non-HTTP applications are known to use port 80 because they assume firewalls would allow those packets through. Also, a small number of HTTP servers run on other ports (see Table A-9). Some devices may allow you to divert packets for these ports as well.
Note that interception caching works anywhere that HTTP traffic is found: close to clients, close to servers, and anywhere in between. Before interception, clients had to be configured to use caching proxies. This meant that most caches were located close to clients. Now, however, we can put a cache anywhere and divert traffic to it. Clients don't need to be told about the proxy. Interception makes it possible to put a cache, or surrogate, close to origin servers. Interception caches can also be located on backbone networks, although I and others feel this is a bad idea, for reasons I'll explain later in this chapter. Fortunately, it's not very common.
The IP Layer: Routing
Interception caching begins at the IP (network) layer, where all sorts of IP packets are routed between nodes. Here, a router or switch recognizes HTTP packets and diverts them to a cache instead of forwarding them to their original destination. There are a number of ways to accomplish the interception:
- Inline
An inline cache is a device that combines both web caching and routing (or bridging) into a single piece of equipment. Inline caches usually have two or more network interfaces. Products from Cacheflow and Network Appliance can operate in this fashion, as can Unix boxes running Squid.
- Layer four switch
Switching is normally a layer two (datalink layer) activity. A layer four switch, however, can make forwarding decisions based on upper layer characteristics, such as IP addresses and TCP port numbers. In addition to HTTP redirection, layer four switches are also often used for server load balancing.
- Web Cache Coordination Protocol
WCCP is an encapsulation protocol developed by Cisco Systems that requires implementation in both a router (or maybe even a switch) and the web cache. Cisco has implemented two versions of WCCP in their router products; both are openly documented as Internet Drafts. Even so, use of the protocol in a product may require licensing from Cisco.
- Cisco policy routing
Policy routing refers to a router's ability to make forwarding decisions based on more than the destination address. We can use this to divert packets based on destination port numbers.
Inline Caches
An inline cache is a single device that performs both routing (or bridging) and web caching. Such a device is placed directly in the network path so it captures HTTP traffic passing through it. HTTP packets are processed by the caching application, while other packets are simply routed between interfaces.
Not many caching products are designed to operate in this manner. An inline cache is a rather obvious single point of failure. Let's face it, web caches are relatively complicated systems and therefore more likely to fail than a simpler device, such as an Ethernet switch. Most caching vendors recommend using a third-party product, such as a layer four switch, when customers need high reliability.
You can build an inexpensive inline cache with a PC, FreeBSD or Linux, and Squid. Any Unix system can route IP packets between two or more network interfaces. Add to that a web cache plus a little packet redirection (as described in "The TCP Layer: Ports and Delivery"), and you've got an inline interception cache. Note that such a system does not have very good failure-mode characteristics. If the system goes down, it affects all network traffic, not just caching. If Squid goes down, all web traffic is affected. It should be possible, however, to develop some clever scripts that monitor Squid's status and alter the packet redirection rules if necessary.
InfoLibria has a product that fits best in the inline category. They actually use two tightly coupled devices to accomplish inline interception caching. The DynaLink is a relatively simple device that you insert into a 100BaseT Ethernet segment. Two of the DynaLink's ports are for the segment you are splitting. The other two deliver packets to and from an attached DynaCache. The DynaLink is a layer one (physical) device. It does not care about Ethernet (layer two) packets or addresses. When the DynaLink is on, electromechanical switches connect the first pair of ports to the second. The DynaCache then skims the HTTP packets off to the cache while bridging all other traffic through to the other side. If the DynaLinks loses power or detects a failure of the cache, the electromechanical switches revert to the passthrough position.
If you want to use an inline caching configuration, carefully consider your reliability requirements and the failure characteristics of individual products. If you choose an inexpensive computer system and route all your traffic through it, be prepared for the fact that a failed disk drive, network card, or power supply can totally cut off your Internet traffic.
Layer Four Switches
[2] You might also hear about ''layer seven'' or ''content routing'' switches. These products have additional features for looking even deeper into network traffic. Unfortunately, there is no widely accepted term to describe all the smart switching products.
Layer four switches also have very nice failure detection features (a.k.a. health checks). If the web cache fails, the switch simply disables redirection and passes the traffic through normally. Similarly, when the cache comes back to life, the switch once again diverts HTTP packets to it. Layer four switches can monitor a device's health in a number of ways, including the following:
- ARP
Of course, this only works for devices that are ''layer two attached'' to the switch. The cache might be on a different subnet, in which case ARP is not used.
- ICMP echo
ICMP round-trip time measurements can sometimes provide additional health information. If the cache is overloaded, or the network is congested, the time between ICMP echo and reply may increase. When the switch notices such an increase, it may send less traffic to the cache.
- TCP
- HTTP
- SNMP
- Round-robin
- Least connections
- Response time
- Packet load
- Address hashing
- URL hashing
With address hashing, the forwarding decision can be made upon receipt of the first TCP packet. With URL hashing, the decision cannot be made until the entire URL has been received. Usually, URLs are quite small, less than 100 bytes, but they can be much larger. If the switch doesn't receive the full URL in the first data packet, it must store the incomplete URL and wait for the remaining piece.
If you have a cluster of caches, URL hashing or destination address hashing are the best choices. Both ensure that the same request always goes to the same cache. This partitioning maximizes your hit ratio and your disk utilization because a given object is stored in only one cache. The other techniques are likely to spread requests around randomly so that, over time, all of the caches come to hold the same objects. We'll talk more about cache clusters in Chapter 9, "Cache Clusters".
Table 5-1 lists switch products and vendors that support layer four redirection. The Linux Virtual Server is an open source solution for turning a Linux box into a redirector and/or load balancer.
Table 5-1. Switches and Products That Support Web Redirection
Vendor Product Line Home Page Alteon, bought by Nortel AceSwitch http://www.alteonwebsystems.com/ Arrowpoint, bought by Cisco Content Smart Switch http://www.arrowpoint.com/ Cisco Local Director http://www.cisco.com/ F5 Labs Big/IP http://www.f5.com/ Foundry ServerIron http://www.foundrynet.com/ Linux Virtual Server LVS http://www.linuxvirtualserver.org/ Radware Cache Server Director http://www.radware.com/ Riverstone Networks Web Switch http://www.riverstonenet.com/ These smart switching products have many more features than I've mentioned here. For additional information, please visit the products' home pages or http://www.lbdigest.com/.
WCCP
Cisco invented WCCP to support interception caching with their router products. At the time of this writing, Cisco has developed two versions of WCCP. Version 1 has been documented within the IETF as an Internet Draft. The most recent version is dated July 2000. It's difficult to predict whether the IETF will grant any kind of RFC status to Cisco's previously proprietary protocols. Regardless, most of the caching vendors have already licensed and implemented WCCPv1. Some vendors are licensing Version 2, which was also recently documented as an Internet Draft. The remainder of this section refers only to WCCPv1, unless stated otherwise.
WCCP consists of two independent components: the control protocol and traffic redirection. The control protocol is relatively simple, with just three message types: HERE_I_AM, I_SEE_YOU, and ASSIGN_BUCKETS. A proxy cache advertises itself to its home router with the HERE_I_AM message. The router responds with an I_SEE_YOU message. The two devices continue exchanging these messages periodically to monitor the health of the connection between them. Once the router knows the cache is running, it can begin diverting traffic.
As with layer four switches, WCCP does not require that the proxy cache be connected directly to the home router. Since there may be additional routers between the proxy and the home router, diverted packets are encapsulated with GRE (Generic Routing Encapsulation, RFC 2784). WCCP is hardcoded to divert only TCP packets with destination port 80. The encapsulated packet is sent to the proxy cache. Upon receipt of the GRE packet, the cache strips off the encapsulation headers and pretends the TCP packet arrived there normally. Packets flowing in the reverse direction, from the cache to the client, are not GRE-encapsulated and don't necessarily flow through the home router.
WCCP supports cache clusters and load balancing. A WCCP-enabled router can divert traffic to many different caches.[3] In its I_SEE_YOU messages, the router tells each cache about all the other caches. The one with the lowest numbered IP address nominates itself as the designated cache. The designated cache is responsible for coming up with a partitioning scheme and sending it to the router with an ASSIGN_BUCKETS message. The buckets -- really a lookup table with 256 entries -- map hash values to particular caches. In other words, the value for each bucket specifies the cache that receives requests for the corresponding hash value. The router calculates a hash function over the destination IP address, looks up the cache index in the bucket table, and sends an encapsulated packet to that cache. The WCCP documentation is vague on a number of points. It does not specify the hash function, nor how the designated cache should divide up the load. WCCPv1 can support up to 32 caches associated with one router.
WCCP also supports failure detection. The cache sends HERE_I_AM messages every 10 seconds. If the router does not receive at least one HERE_I_AM message in a 30-second period, the cache is marked as unusable. Requests are not diverted to unusable caches. Instead, they are sent along the normal routing path towards the origin server. The designated cache can choose to reassign the unusable cache's buckets in a future ASSIGN_BUCKETS message.
WCCPv1 is supported in Cisco's IOS versions 11.1(19)CA, 11.1(19)CC, 11.2(14)P, and later. WCCPv2 is supported in all 12.0 and later versions. Most IOS 12.x versions also support WCCPv1, but 12.0(4)T and earlier do not. Be sure to check whether your Cisco hardware supports any of these IOS versions.
When configuring WCCP in your router, you should refer to your Cisco documentation. Here are the basic commands for IOS 11.x:
ip wccp enable ! interface fastethernet0/0 ip wccp web-cache redirectUse the following commands for IOS 12.x:
ip wccp version 1 ip wccp web-cache ! interface fastethernet0/0 ip wccp web-cache redirect outNotice that with IOS 12.x you need to specify which WCCP version to use. This command is only available in IOS releases that support both WCCP versions, however. The fastethernet0/0 interface may not be correct for your installation; use the name of the router interface that connects to the outside Internet. Note that packets are redirected on their way out of an interface. IOS does not yet support redirecting packets on their way in to the router. If needed, you can use access lists to prevent redirecting requests for some origin server or client addresses. Consult the WCCP documentation for full details.
Cisco Policy Routing
Interception caching can also be accomplished with Cisco policy routing. The next-hop for an IP packet is normally determined by looking up the destination address in the IP routing table. Policy routing allows you to set a different next-hop for packets that match a certain pattern, specified as an IP access list. For interception caching, we want to match packets destined for port 80, but we do not want to change the next-hop for packets originating from the cache. Thus, we have to be a little bit careful when writing the access list. The following example does what we want:
access-list 110 deny tcp host 10.1.2.3 any eq www access-list 110 permit tcp any any eq www10.1.2.3 is the address of the cache. The first line excludes packets with a source address 10.1.2.3 and a destination port of 80 (www). The second line matches all other packets destined for port 80. Once the access list has been defined, you can use it in a route-map statement as follows:
route-map proxy-redirect permit 10 match ip address 110 set ip next-hop 10.1.2.3Again, 10.1.2.3 is the cache's address. This is where we want the packets to be diverted. The final step is to apply the policy route to specific interfaces:
interface Ethernet0 ip policy route-map proxy-redirectThis instructs the router to check the policy route we specified for packets received on interface Ethernet0.
On some Cisco routers, policy routing may degrade overall performance of the router. In some versions of the Cisco IOS, policy routing requires main CPU processing and does not take advantage of the ''fast path'' architecture. If your router is moderately busy in its normal mode, policy routing may impact the router so much that it becomes a bottleneck in your network.
Some amount of load balancing can be achieved with policy routing. For example, you can apply a different next-hop policy to each of your interfaces. It might even be possible to write a set of complicated access lists that make creative use of IP address netmasks.
Note that policy routing does not support failure detection. If the cache goes down or stops accepting connections for some reason, the router blindly continues to divert packets to it. Policy routing is only a mediocre replacement for sophisticated layer four switching products. If your production environment requires high availability, policy routing is probably not for you.
The TCP Layer: Ports and Delivery
Now that we have fiddled with the routing, the diverted HTTP packets are arriving at the cache's network interface. Usually, an Internet host rejects received packets if the destination address does not match the host's own IP address. For interception caching to work, the cache must accept the diverted packet and give it to the TCP layer for processing.
In this section, we'll discuss how to configure a Unix host for interception caching. If you use a caching appliance, where the vendor supplies both hardware and software, this section may not be of interest to you.
The features necessary to support interception caching on Unix rely heavily on software originally developed for Internet firewalls. In particular, interception caching makes use of the software for packet filtering and, in some cases, network address translation. This software does two important things. First, it tells the kernel to accept a diverted packet and give it to the TCP layer. Second, it gives us the option to change the destination port number. The diverted packets are destined for port 80, but our cache might be listening on a different port. If so, the filtering software changes the port number to that of the cache before giving the packet to the TCP layer.
I'm going to show you three ways to configure interception caching: first with Linux, then with FreeBSD, and finally with the IP Filter package, which runs on numerous Unix flavors. In all the examples, 10.1.2.3 is the IP address of the cache (and the machine that we are configuring). The examples also assume that the cache is running on port 3128, and that an HTTP server, on port 80, is also running on the system.
Linux
Linux has a number of different ways to make interception caching work. Mostly, it depends on your kernel version number. For Linux-2.2 kernels, you'll probably want to use ipchains; for 2.4 kernels, you'll want to use iptables (a.k.a. Netfilter).
Most likely, the first thing you'll need to do is compile a kernel with certain options enabled. If you don't already know how to build a new kernel, you'll need to go figure that out, and then come back here. A good book to help you with this is Linux in a Nutshell [{XREF}]. Also check out the "Linux Kernel HOWTO" from the Linux Documentation Project at http://www.linuxdoc.org/.
ipchains
# make menuconfigUnder Networking options, make sure the following are set:
[*] Network firewalls [*] Unix domain sockets [*] TCP/IP networking [*] IP: firewalling [*] IP: always defragment (required for masquerading) [*] IP: transparent proxy supportOnce the kernel has been configured, you need to actually build it, install it, and then reboot your system.
After you have a running kernel with the required options set, you need to familiarize yourself with the ipchains program. ipchains is used to configure IP firewall rules in Linux. Firewall rules can be complicated and unintuitive to many people. If you are not already familiar with ipchains, you should probably locate another reference that describes in detail how to use it.
The Linux IP firewall has four rule sets: input, output, forwarding, and accounting. For interception caching, you need to configure only the input rules. Rules are evaluated in order, so you need to list any special cases first. This example assumes we have an HTTP server on the Linux host, and we don't want to redirect packets destined for that server:
/sbin/ipchains -A input -p tcp -s 0/0 -d 10.1.2.3/32 80 -j ACCEPT /sbin/ipchains -A input -p tcp -s 0/0 -d 0/0 80 -j REDIRECT 3128The -A input option means we are appending to the set of input rules. The -p tcp option means the rule matches only TCP packets. The -s and -d options specify source and destination IP addresses with optional port numbers. Using 0/0 matches any IP address. The first rule accepts all packets destined for the local HTTP server. The second rule matches all other packets destined for port 80 and redirects them to port 3128 on this system, which is where the cache accepts connections.
Finally, you need to enable routing on your system. The easiest way to do this is with the following command:
echo 1 > /proc/sys/net/ipv4/ip_forwardAfter you get the ipchains rules figured out, be sure to save them to a script that gets executed every time your machine boots up.
iptables
/sbin/iptables -t nat -D PREROUTING -i eth0 -p tcp --dport 80 \ -j REDIRECT --to-port 3128You'll also need to enable routing, as described previously.
Since iptables is relatively new, the information here may be incomplete. Search for Daniel's mini-HOWTO or see the Squid FAQ (http://www.squid-cache.org/Doc/FAQ/) for further information.
FreeBSD
Configuring FreeBSD for interception caching is very similar to configuring Linux. The examples here are known to work for FreeBSD Versions 3.x and 4.x. These versions have all the necessary software in the kernel source code, although you need to specifically enable it. If you are stuck using an older version (like 2.2.x), you should consider upgrading, or have a look at the IP Filter software described in the following section.
First, you probably need to generate a new kernel with the IP firewall code enabled. If you are unfamiliar with building kernels, read the config(8) manual page. The kernel configuration files can usually be found in /usr/src/sys/i386/conf. Edit your configuration file and make sure these options are enabled:
options IPFIREWALL options IPFIREWALL_FORWARDNext, configure and compile your new kernel as described in the config(8) manual page. After your new kernel is built, install it and reboot your system.
You need to use the ipfw command to configure the IP firewall rules. The following rules should get you started:
/sbin/ipfw add allow tcp from any to 10.1.2.3 80 in /sbin/ipfw add fwd 127.0.0.1,3128 tcp from any to any 80 in /sbin/ipfw add allow any from any to anyThe first rule allows incoming packets destined for the HTTP server on this machine. The second line causes all remaining incoming packets destined for port 80 to be redirected (forwarded, in the ipfw terminology) to our web cache on port 3128. The final rule allows all remaining packets that didn't match one of the first two. The final rule is shown here because FreeBSD denies remaining packets by default.
A better approach is to write additional allow rules just for the services running on your system. Once all the rules and services are working, you can have FreeBSD deny all remaining packets. If you do that, you'll need some special rules so the interception proxy works:
/sbin/ipfw add allow tcp from any 80 to any out /sbin/ipfw add allow tcp from 10.1.2.3 to any 80 out /sbin/ipfw add allow tcp from any 80 to 10.1.2.3 in established /sbin/ipfw add deny any from any to anyThe first rule here matches TCP packets for intercepted connections sent from the proxy back to the clients. The second rule matches packets for connections that the proxy opens to origin servers. The third rule matches packets from the origin servers coming back to the proxy. The final rule denies all other packets. Note that this configuration is incomplete. It's likely that you'll need to add additional rules for services such as DNS, NTP, and SSH.
Once you have the firewall rules configured to your liking, be sure to save the commands to a script that is executed when your system boots up.
Other Operating Systems
If you don't use Linux or FreeBSD, you might still be able to use interception caching. The IP Filter package runs on a wide range of Unix systems. According to their home page (http://cheops.anu.edu.au/~avalon/ip-filter.html), IP Filter works with FreeBSD, NetBSD, OpenBSD, BSD/OS, Linux, Irix, SunOS, Solaris, and Solaris-x86.
As with the previous Linux and FreeBSD instructions, IP Filter also requires kernel modifications. Some operating systems support loadable modules, so you might not actually need to build a new kernel. Configuring the kernels of all the different platforms is too complicated to cover here; see the IP Filter documentation regarding your particular system.
Once you have made the necessary kernel modifications, you can write an IP Filter configuration file. This file contains the redirection rules for interception caching:
rdr ed0 10.1.2.3/32 port 80 -> 127.0.0.1 port 80 tcp rdr ed0 0.0.0.0/0 port 80 -> 127.0.0.1 port 3128 tcpNote that the second field is a network interface name; the name ed0 may not be appropriate for your system.
To install the rules, you must use the ipnat program. Assuming that you saved the rules in a file named /etc/ipnat.rules, you can use this command:
/sbin/ipnat -f /etc/ipnat.rulesThe IP Filter package works a little differently than the Linux and FreeBSD firewalls. In particular, the caching application needs to access /dev/nat to determine the proper destination IP address. Thus, your startup script should also make sure the caching application has read permission on the device:
chgrp nobody /dev/ipnat chmod 644 /dev/ipnatIf you are using Squid, you need to tell it to compile in IP Filter support with the - -enable-ipf-transparent configure option.
The Application Layer: HTTP
Recall that standard HTTP requests and proxy-HTTP requests are slightly different (see Section "HTTP Requests"). The first line of a standard request normally includes only an absolute pathname. Proxy-HTTP requests, on the other hand, use the full URL. Because interception proxying does not require browser configuration, and the browser thinks it is connected directly to an origin server, it sends only the URL-path in the HTTP request line. The URL-path does not include the origin server hostname, so the cache must determine the origin server hostname by some other means.
The most reliable way to determine the origin server is from the HTTP/1.1 &Host; header. Fortunately, all of the recent browser products do send the &Host; header, even if they use "HTTP/1.0" in the request line. Thus, it is a relatively simple matter for the cache to transform this standard request:
GET /index.html HTTP/1.0 Host: www.ircache.netinto a proxy-HTTP request, such as:
GET http://www.ircache.net/index.html HTTP/1.0In the absence of the &Host; header, the cache might be able to use the socket interface to get the IP address for which the packet was originally destined. The Unix sockets interface allows an application to retrieve the local address of a connected socket with the getsockname() function. In this case, the local address is the origin server that the proxy pretends to be. Whether this actually works depends on how the operating system implements the packet redirection. The native Linux and FreeBSD firewall software preserves the destination IP address, so getsockname() does work. The IP Filter package does not preserve destination addresses, so applications need to access /dev/nat to get the origin server's IP address.
If the cache uses getsockname() or /dev/nat, the resulting request looks something like this:
GET http://192.52.106.29/index.html HTTP/1.0While either a hostname or an IP address can be used to build a complete URL, hostnames are highly preferable. The primary reason for this is that URLs typically use hostnames instead of IP addresses. In most cases, a cache cannot recognize that both forms of a URL are equivalent. If you first request a URL with a hostname, and then again with its IP address, the second request is a cache miss, and the cache now stores two copies of the same object. This problem is made worse because some hostnames have many different IP addresses.
Debugging Interception
Many people seem to have trouble configuring interception caching on their networks. This is not too surprising, because configuration requires a certain level of familiarity with switches and routers. The rules and access lists these devices use to match certain packets are particularly difficult. If you set up interception caching and it doesn't seem to be working, these hints may help you isolate the problem.
First of all, does the caching proxy receive redirected connections? The best way to determine this is with tcpdump. For example, you can use:
tcpdump -n port 80You should see a fair amount of output if the switch or router is actually diverting connections to the proxy. Note that if you have an HTTP server running on the same machine, it is difficult to visually differentiate the proxy traffic from the server traffic. You can use additional tcpdump parameters to filter out the HTTP server traffic:
tcpdump -n port 80 and not dst 10.1.2.3If you don't see any output from tcpdump, then it's likely your router/switch is incorrectly configured.
If your browser requests just hang, then it's likely that the switch is redirecting traffic, but the cache cannot forward misses. Running tcpdump in this case shows a lot of TCP SYN packets sent out but no packets coming back in. You can also check for this condition by running netstat -n. If you see a lot of connections in the SYN_SENT state, it is likely that the firewall/nat rules deny incoming packets from origin servers. Turn on firewall/nat debugging if you can.
You may also find that your browser works fine, but the caching proxy doesn't log any of the requests. In this case, the proxy machine is probably simply routing the packets. This could happen if you forget, or mistype, the redirect/forward rule in the ipchains/ipfw configuration.
Issues
It's Difficult for Users to Bypass
If for some reason, one of your users encounters a problem with interception caching, he or she is going to have a difficult time getting around the cache. Possible problems include stale pages, servers that are incompatible with your cache (but work without it), and IP-based access controls. The only way to get around an interception cache is to configure a different proxy cache manually. Then the TCP packets are not sent to port 80 and thus are not diverted to the cache. Most likely, the user is not savvy enough to configure a proxy manually, let alone realize what the problem is. And even if he does know what to do, he most likely does not have access to another proxy on the Internet.
In my role as a Squid developer, I've received a number of email messages asking for help bypassing ISP settings. The following message is real; only the names have been changed to protect the guilty:
Duane, I am Zach Ariah, a subscriber of XXX Internet - an ISP who has recently installed... Squid/1.NOVM.21. All of my HTTP requests are now being forced through the proxy(proxy-03-real.xxxxx.net). I really don't like this, and am wondering if there is anyway around this. Can I do some hack on my client machine, or put something special into the browser, which will make me bypass the proxy??? I know the proxy looks at the headers. This is why old browsers don't work. Anyway... Please let me know what's going on with this. Thank you and Best regards, Zach AriahThis is a more serious issue for ISPs than it is for corporations. Users in a corporate environment are more likely to find someone who can help them. Also, corporate users probably expect their web traffic to be filtered and cached. ISP customers have more to be angry about, since they pay for the service themselves.
All layer four switching and routing products have the ability to bypass the cache for special cases. For example, you can tell the switch to forward packets normally if the origin server is www.hotmail.com or if the request is from the user at 172.16.4.3. However, only the administrator can change the configuration. Users who experience problems need to ask the administrator for assistance. Getting help may take hours, or even days. In some cases, users may not understand the situation well enough to ask for help. It's also likely that such a request will be misinterpreted or perhaps even ignored. ISPs and other organizations that deploy interception caching must be extremely sensitive to problem reports from users trying to surf the Web.
Packet Transport Service
As someone who understands a little about the Internet, I have certain expectations about the way in which my ISP handles my packets. When my computer sends a TCP/IP packet to my ISP, I expect my ISP to forward that packet towards its destination address. If my ISP does something different, such as divert my packets to a proxy cache, I might feel as though I'm not getting the service that I pay for.
But what difference does it make? If I still get the information I requested, what's wrong with that? One problem is related to the issues raised in Chapter 3, "Politics of Web Caching". Users might assume that their web requests cannot be logged because they have not configured a proxy.
Another, more subtle point to be made is that some users of the network expect the network to behave predictably. The standards that define TCP connections and IP routing do not allow for connections to be diverted and accepted under false pretense. When I send a TCP/IP packet, I expect the Internet infrastructure to handle that packet as described in the standards documents. Predictability also means that a TCP/IP packet destined for port 80 should be treated just like a packet for ports 77, 145, and 8333.
Routing Changes
Some origin servers expect all requests from a client to come from the same IP address. This can really be a problem if the server uses HTTP/TLS and unencrypted HTTP. The unencrypted (port 80) traffic may be intercepted and sent through a caching proxy; the encrypted traffic is not intercepted. Thus, the two types of requests come from two different IP addresses. Imagine that the server creates some session information and associates the session with the IP address for unencrypted traffic. If the server instructs the client to make an HTTP/TLS request using the same session, it may refuse the request because the IP address doesn't match what it expects. Given the high proliferation of caching proxies today, it is unrealistic for an origin server to make this requirement. The session key alone should be sufficient, and the server shouldn't really care about the client's IP address.
When an interception cache is located on a different subnet from the clients using the cache, a particularly confusing situation may arise. The cache may be unable to reach an origin server for whatever reason, perhaps because of a routing glitch. However, the client is able to ping the server directly or perhaps even telnet to it and see that it is alive and well. This can happen, of course, because the ping (ICMP) and telnet packets take a different route than HTTP packets. Most likely, the redirection device is unaware that the cache cannot reach the origin server, so it continues to divert packets for that server to the cache.
It Affects More Than Browsers and Users
Web caches are deployed primarily for the benefit of humans sitting at their computers, surfing the Internet. However, a significant amount of HTTP traffic does not originate from browsers. The client might instead be a so-called web robot, or a program that mirrors entire web sites, or any number of other things. Should these clients also use proxy caches? Perhaps, but the important thing is that with interception proxying, they have no choice.
This problem manifested itself in a sudden and very significant way in June of 1998, when Digex decided to deploy interception caching on their backbone network. The story also involves Cybercash, a company that handles credit card payments on the Internet. The Cybercash service is built behind an HTTP server, thus it uses port 80. Furthermore, Cybercash uses IP-based authentication for its services. That is, Cybercash requires transaction requests to come from the known IP addresses of its customers. Perhaps you can see where this is leading.
A number of other companies that sell merchandise on the Internet are connected through Digex's network. When a purchase is made at one of these sites, the merchant's server connects to Cybercash for the credit card transaction. However, with interception caching in place on the Digex network, Cybercash received these transaction connections from a cache IP address instead of the merchant's IP address. As a result, many purchases were denied until people finally realized what was happening.
The incident generated a significant amount of discussion on the North American Network Operators Group (NANOG) mailing list. Not everyone was against interception caching; many applauded Digex for being forward-thinking. However, this message from Jon Lewis (jlewis@fdt.net) illustrates the feelings of people who are negatively impacted by interception caching:
My main gripe with Digex is that they did this (forced our traffic into a transparent proxy) without authorization or notification. I wasted an afternoon, and a customer wasted several days worth of time over a 2-3 week period trying to figure out why their cybercash suddenly stopped working. This customer then had to scan their web server logs, figure out which sales had been "lost" due to proxy breakage, and see to it that products got shipped out. This introduced unusual delays in their distribution, and had their site shut down for several days between their realization of a problem and resolution yesterday when we got Digex to exempt certain IP's from the proxy.
Others took an even stronger stance against interception caching. For example, Karl Denninger (karl@denninger.net) wrote:
Well, I'd love to know where they think they get the authority to do this from in the first place.... that is, absent active consent. I'd be looking over contracts and talking to counsel if someone tried this with transit connections that I was involved in. Hijacking a connection without knowledge and consent might even run afoul of some kind of tampering or wiretapping statute (read: big trouble).....
No-Intercept Lists
The maintenance of a no-intercept list is a significant administrative headache. Proxy cache operators cannot really be expected to know of every origin server that breaks with interception caching. At the same time, discovering the list of servers the hard way makes the lives of users and technical support staff unnecessarily difficult. A centrally maintained list has certain appeal, but it would require a standard format to work with products from different vendors.
One downside to a no-divert list is that it may also prevent useful caching of some objects. Routers and switches check only the destination IP address when deciding whether to divert a connection. Any given server might have a large amount of cachable content but only a small subset of URLs that do not work through caches. It is unfortunate that the entire site must not be diverted in this case.
Are Port 80 Packets Always HTTP?
I've already made the point that packets destined for port 80 may not necessarily be HTTP. The implied association between protocols and port numbers is very strong for low-numbered ports. Everyone knows that port 23 is telnet, port 21 is FTP, and port 80 is HTTP. However, these associations are merely conventions that have been established to maximize interoperation.
Nothing really stops me from running a telnet server on port 80 on my own system. The telnet program has the option to connect to any port, so I just need to type telnet myhostname 80. However, this won't work if there is an interception proxy between my telnet client and the server. The router or switch assumes the port 80 connection is for an HTTP request and diverts it to the cache.
This issue is likely to be of little concern to most people, especially in corporate networks. Only a very small percentage of port 80 traffic is not really HTTP. In fact, some administrators see it as a positive effect, because it can prevent non-HTTP traffic from entering their network.
HTTP Interoperation Problems
[4]See Microsoft Knowledgebase article Q266121, http://support.microsoft.com/support/kb/articles/Q266/1/21.ASP.
Interception proxies also pose problems for maintaining backwards compatibility. HTTP allows clients and servers to utilize new, custom request methods and headers. Ideally, proxy caches should be able to pass unknown methods and headers between the two sides. However, in practice, many caching products cannot process new request methods. A smart client can bypass the proxy cache for the unknown methods, unless interception caching is used.
IP Interoperation Problems
[5] The Maximum Transmission Unit is the largest packet size that can be sent in a single datalink-layer frame or cell.
Another problem arises when attempting to measure network proximity. One way to estimate how close you are to another server is to time how long it takes to open a TCP connection. Using this technique with an interception proxy in the way produces misleading results. Connections to port 80 are established quickly and almost uniformly. Connections to other ports, however, take significantly longer and vary greatly. A similar measurement tactic times how long it takes to complete a simple HTTP request. Imagine that you've developed a service that rates content providers based on how quickly their origin servers respond to your requests. Everything is working fine, until one day your ISP installs an interception cache. Now you're measuring the proxy cache rather than the origin servers.
I imagine that as IP security (RFC 2401) becomes more widely deployed, many people will discover problems caused by interception proxies. The IP security protocols and architecture are designed to ensure that packets are delivered end-to-end without modification. Indeed, connection hijacking is precisely one of the reasons to use IP security.
To Intercept or Not To Intercept
A related benefit is the sheer number of users using the cache. When users are given a choice to use proxies, most choose not to. With interception caching, however, they have no choice. The larger user base drives up hit ratios and saves more wide-area Internet bandwidth.
The most significant drawback to interception caching is that users lose some control over their web traffic. When problems occur, they can't fix the problem themselves, assuming they even know how. Another important consequence of connection hijacking is that it affects more than just end users and web browsers. This is clearly evident in the case of Digex and Cybercash.
Certainly, interception caching was in use long before Digex decided to use it on their network. Why, then, did the issue with Cybercash never come up until then? Mostly because Digex was the first to deploy interception caching in a backbone network. Previously, interception caching had been installed close to web clients, not web servers. There seems to be growing consensus in the Internet community that interception caching is acceptable at the edges of the network, where its effects are highly localized. When used in the network core (i.e., backbones), its effects are widely distributed and difficult to isolate, and thus unacceptable.
Many people feel that WPAD (or something similar) is a better way to ''force'' clients to use a caching proxy. With WPAD, clients at least understand that they are talking to a proxy rather than the origin server. Of course, there's no reason you can't use both. If you use interception proxying, you can still use WPAD to configure those clients that support it.
Back to: Web Caching
© 2001, O'Reilly & Associates, Inc.
webmaster@oreilly.com