Figure 2.1-1: Application processes, sockets, and the underlying
transport protocol.
Network applications are the raisons d'etre of a computer network. If we couldn't conceive of any useful applications, there wouldn't be any need to design networking protocols to support them. But over the past 35 years, many people have devised numerous ingenious and wonderful networking applications. These applications include the classic text-based applications that became popular in the 1980s, including remote access to computers, electronic mail, file transfers, newsgroups, and chat. But they also include more recently conceived multimedia applications, such as the World Wide Web, Internet telephony, Internet radio, video conferencing, and streaming audio and video. And they include the 2 killer applications introduced at the end of the millennium - instant messaging with contact lists, and peer-to-peer (P2P) file sharing.
Although network applications are diverse and have many interacting components, software is almost always at their core. Recall from Section 1.2 that for a network application's software is distributed among two or more end systems (i.e., host computers). For example, with the Web there are two pieces of software that communicate with each other: the browser software in the user's host (PC, Mac or workstation), and the Web server software in the Web server. With Telnet, there are again two pieces of software in two hosts: software in the local host and software in the remote host. With multiparty video conferencing, there is a software piece in each host that participates in the conference.
In the jargon of operating systems, it is not actually software pieces (i.e., programs) that are communicating but in truth processes that are communicating. A process can be thought of as a program that is running within an end system. When communicating processes are running on the same end system, they communicate with each other using interprocess communication. The rules for interprocess communication are governed by the end system's operating system. But in this book we are not interested in how processes on the same host communicate, but instead in how processes running on different end systems (with potentially different operating systems) communicate. Processes on two different end systems communicate with each other by exchanging messages across the computer network. A sending process creates and sends messages into the network; a receiving process receives these messages and possibly responds by sending messages back. Networking applications have application-layer protocols that define the format and order of the messages exchanged between processes, as well as the actions taken on the transmission or receipt of a message.
The application layer is a particularly good place to start our study of protocols. It's familiar ground. We're acquainted with many of the applications that rely on the protocols we will study. It will give us a good feel for what protocols are all about, and will introduce us to many of the same issues that we'll see again when we study transport, network, and data link layer protocols.
Network Application Architectures
When building a new network application, you'll first need to decide on the
application's architecture. Keep in mind that an application's architecture is
distinctly different from the network architecture (e.g. 7-layer OSI or 5-layer
Internet architecture). From the application developer's perspective, the
network architecture is fixed and provides a specific set of services to
applications. The application architecture, on the other hand, is
designed by the application developer and dictates how the application is
organized over the various end systems. In choosing the application
architecture, an application developer will likely draw on one of the 3
predominant architectures used in modern network applications: the
client-server, the P2P or a hybrid of the client-server and P2P architectures.
In a client-server architecture, there is always-on host, called the
server, which services requests from many other hosts, called clients.
The client hosts can be either sometimes-on or always-on. A classic example is
the Web application for which an always-on Web server services requests from
browsers running on client hosts. When a Web server receives a request for an
object from a client host, it responds by sending the requested object the the
client host. Note that with the client-server architecture, clients do not
directly communicate with each other. Another characteristic of the
client-server architecture is that the server has a fixed, well-known address,
called in IP address. Because the server has a fixed, well-known address, and
because the server is always on, a client can always contact the server by
sending a packet to the server's address. Some of the better-known applications
with a client-server architecture include the Web, file transfer, remote login,
and e-mail.
Often in a client-server application, a single server host is incapable of
keeping up with all the requests from its clients. For example, a popular news
Web site can quickly become overwhelmed if it has only one server handling all
of its requests. For this reason, clusters of hosts - sometimes referred to as a
server farm - are often used to create a powerful virtual server in
client-server architectures.
In a pure P2P architecture, there isn't an always-on
server at the center of the application. Instead, arbitrary pairs of hosts,
called peers, communicate directly with each other. Because the peers
communicate without passing through some special server, the architecture is
called peer-to-peer. In the P2P architecture, none of the participating hosts is
required to be always on; in addition, a participating host may change its IP
address each time it comes on. A nice example of application that has a pure P2P
architecture is Gnutella, an open-source P2P file-sharing application. In
Gnutella, any host can request files, send files, query to find where a file is
located, respond to queries, and forward queries.
One of the greatest strengths of the P2P architectures is its
scalability. For example, in a P2P file-sharing application, millions of peers
may participate in the file-sharing community, with each one functioning as a
server and contributing resources to the community. Thus, while each peer will
generate workload by requesting files, each peer also adds service capacity to
the system by responding to the requests of other peers. In today's Internet,
P2P file-sharing traffic accounts for a major fraction of all traffic.
On the other hand, because the highly distributed and
decentralized nature of P2P applications, they can be difficult to manage. For
example, one peer may have the only copy of an important file, and that peer can
drop out of the community an any time. It remains an open question whether it is
possible to build industrial-strength P2P solutions for enterprise applications.
Client-server and P2P are 2 common architectures for network
applications. However, many applications are organized as hybrids of the
client-server and P2P architectures. One such example is Napster, which was the
first of the popular MP3 file-sharing applications. Napster is P2P in the sense
that MP3 files are exchanged directly among peers, without passing through
dedicated, always-on servers; but Napster is also client-server in the sense
that a peer queries a central server to determine which currently-up peers have
a desired MP3 file. Another application that users hybrid architecture is
instant messaging. In instant messaging, the chatting between two users is
typically P2P; that is, the text sent between the two users does not pass
through an always-on, intermediate server. However, when Alice launches her
instant messaging application, she registers herself at a central server; and
when Bob wants to chat with someone on his buddy list, his instant messaging
client contact the central server to find out which buddies are currently online
and available.
Processes Communicating Across a Network
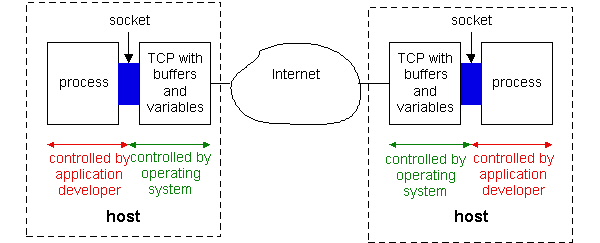
As noted above, an application involves two processes in two different hosts communicating with each other over a network. A network application consists of pairs of processes that send messages to each other over a network. For example, in the Web application a client browser process exchanges messages with a Web server process. In a P2P file-sharing system, a file is transferred from a process in one peer to a process in another peer. For each pair of communicating processes, we typically label on of the two processes as the client and the other process as the server. With P2P file sharing, the peer that is downloading the file is labeled as the client, and the peer that is uploading the file is labeled as the server. In some applications, a process can be both a client and server. In the context of a communication session between a pair of processes, the process that initiates the communication (that is, initially contacts the other process at the beginning of the session) is labeled as the client. The process that waits to be contacted to begin the session is the server. The two processes communicate with each other by sending and receiving messages through their sockets. A process's socket can be thought of as the process's door: a process sends messages into, and receives message from, the network through its socket. When a process wants to send a message to another process on another host, it shoves the message out its door. The process assumes that there is a transportation infrastructure on the other side of the door that will transport the message to the door of the destination process.
Figure 2.1-1: Application processes, sockets, and the underlying
transport protocol.
Figure 2.1-1 illustrates socket communication between two processes that communicate over the Internet. (The figure assumes that the underlying transport protocol is TCP, although the UDP protocol could be used as well in the Internet.) As shown in this figure, a socket is the interface between the application layer and the transport layer within a host. It is also referred to as the API (application programmers interface) between the application and the network, since the socket is the programming interface with which networked applications are built in the Internet.. The application developer has control of everything on the application-layer side of the socket but has little control of the transport-layer side of the socket. The only control that the application developer has on the transport-layer side is (i) the choice of transport protocol and (ii) perhaps the ability to fix a few transport-layer parameters such as maximum buffer and maximum segment sizes. Once the application developer chooses a transport protocol (if a choice is available), the application is built using the transport layer the services offered by that protocol.
In order for a process on one host to send a message to a process on another host, the sending process must identify the receiving process. To identify the receiving process, one must typically specify two pieces of information: (i) the name or address of the host machine, and (ii) an identifier that specifies the identity of the receiving process on the destination host.
Let us first consider host addresses. In Internet applications, the destination host is specified by its IP address. For now, it suffices to know that the IP address is a 32-bit quantity that uniquely identifies the end-system (more precisely, it uniquely identifies the interface that connects that host to the Internet). Since the IP address of any end system connected to the public Internet must be globally unique, the assignment of IP addresses must be carefully managed.
In addition to knowing the address of the end system to which a message is destined, a sending application must also specify information that will allow the receiving end system to direct the message to the appropriate process on that system. A receive-side port number serves this purpose in the Internet. Popular application-layer protocols have been assigned specific port numbers. For example, a Web server process (which uses the HTTP protocol) is identified by port number 80. A mail server (using the SMTP) protocol is identified by port number 25. A list of well-known port numbers for all Internet standard protocols can be found at http://www.iana.org. When a developer creates a new network application, the application must be assigned a new port number.
Application-Layer Protocols
It is important to distinguish between network applications and application-layer protocols. An application-layer protocol is only one piece (albeit, a big piece) of a network application. Let's look at a couple of examples. The Web is a network application that allows users to obtain "documents" from Web servers on demand. The Web application consists of many components, including a standard for document formats (i.e., HTML), Web browsers (e.g., Netscape Navigator and Internet Explorer), Web servers (e.g., Apache, Microsoft and Netscape servers), and an application-layer protocol. The Web's application-layer protocol, HTTP (the HyperText Transfer Protocol [RFC 2068]), defines how messages are passed between browser and Web server. Thus, HTTP is only one piece (albeit, a big piece) of the Web application. As another example, consider the Internet electronic mail application. Internet electronic mail also has many components, including mail servers that house user mailboxes, mail readers that allow users to read and create messages, a standard for defining the structure of an email message (i.e., MIME) and application-layer protocols that define how messages are passed between servers, how messages are passed between servers and mail readers, and how the contents of certain parts of the mail message (e.g., a mail message header) are to be interpreted. The principal application-layer protocol for electronic mail is SMTP (Simple Mail Transfer Protocol [RFC 821]). Thus, SMTP is only one piece (albeit, a big piece) of the email application.
As noted above, an application layer protocol defines how an application's processes, running on different end systems, pass messages to each other. In particular, an application layer protocol defines:
Some application-layer protocols are specified in RFCs and are therefore in the public domain. For example, HTTP is available as an RFC. If a browser developer follows the rules of the HTTP RFC, the browser will be able to retrieve Web pages from any Web server (more precisely, any Web server that has also followed the rules of the HTTP RFC). Many other application-layer protocols are proprietary and intentionally not available in the public domain. For example, many of the existing Internet phone products use proprietary application-layer protocols.
Recall that a socket is the interface between the application process and the transport protocol. The application at the sending side sends messages through the door. At the other side of the door, the transport protocol has the responsibility of moving the messages across the network to the door at the receiving process. Many networks, including the Internet, provide more than one transport protocol. When you develop an application, you must choose one of the available transport protocols. How do you make this choice? Most likely, you will study the services that are provided by the available transport protocols, and you will pick the protocol with the services that best match the needs of your application. The situation is similar to choosing either train or airplane transport for travel between two cities (say New York City and Boston). You have to choose one or the other, and each transport mode offers different services. (For example, the train offers downtown pick up and drop off, whereas the plane offers shorter transport time.)
What services might a network application need from a transport protocol? We can broadly classify an application's service requirements along three dimensions: data loss, bandwidth, and timing.
Figure 2.1-2 summarizes the reliability, bandwidth, and timing requirements
of some popular and emerging Internet applications.
| Application | Data Loss | Bandwidth | Time sensitive? |
| file transfer | no loss | elastic | no |
| electronic mail | no loss | elastic | no |
| Web documents | no loss | elastic (few kbps) | no |
| real-time audio/video | loss-tolerant | audio: few Kbps to 1Mbps
video: 10's Kbps to 5 Mbps |
yes: 100's of msec |
| stored audio/video | loss-tolerant | same as interactive audio/video | yes: few seconds |
| interactive games | loss-tolerant | few Kbps to 10's Kbps | yes: 100's msecs |
| Instant messaging | No loss | elastic | yes and no |
Figure 2.1-2: Requirements of selected network applications.
Figure 2.1-2 outlines only a few of the key requirements of a few of the more popular Internet applications. Our goal here is not to provide a complete classification, but simply to identify a few of the most important axes along which network application requirements can be classified.
The Internet (and more generally TCP/IP networks) makes available two transport protocols to applications, namely, UDP (User Datagram Protocol) and TCP (Transmission Control Protocol). When a developer creates a new application for the Internet, one of the first decisions that the developer must make is whether to use UDP or TCP. Each of these protocols offers a different service model to the invoking applications.
TCP Services
The TCP service model includes a connection-oriented service and a reliable data transfer service. When an application invokes TCP for its transport protocol, the application receives both of these services from TCP.
TCP also includes a congestion control mechanism, a service for the general welfare of the Internet rather than for the direct benefit of the communicating processes. The TCP congestion control mechanism throttles a process (client or server) when the network is congested. In particular, as we shall see in Chapter 3, TCP congestion control attempts to limit each TCP connection to its fair share of network bandwidth.
The throttling of the transmission rate can have a very harmful effect on real-time audio and video applications that have minimum bandwidth requirements. Moreover, real-time applications are loss-tolerant and do not need a fully reliable transport service. In fact, the TCP acknowledgments and retransmissions that provide the reliable transport service (discussed in Chapter 3) can further slow down the transmission rate of useful real-time data. For these reasons, developers of real-time applications usually run their applications over UDP rather than TCP.
Having outlined the services provided by TCP, let us say a few words about the services that TCP does not provide. First, TCP does not guarantee a minimum transmission rate. In particular, a sending process is not permitted to transmit at any rate it pleases; instead the sending rate is regulated by TCP congestion control, which may force the sender to send at a low average rate. Second, TCP does not provide any delay guarantees. In particular, when a sending process passes a message into a TCP socket, the message will eventually arrive to receiving socket, but TCP guarantees absolutely no limit on how long the message may take to get there. As many of us have experienced with the World Wide Wait, one can sometimes wait tens of seconds or even minutes for TCP to deliver a message (containing, for example, an HTML file) from Web server to Web client. In summary, TCP guarantees delivery of all data, but provides no guarantees on the rate of delivery or on the delays experienced by individual messages.
UDP is a no-frills, lightweight transport protocol with a minimalist service model. UDP is connectionless, so there is no handshaking before the two processes start to communicate. UDP provides an unreliable data transfer service, that is, when a process sends a message into a UDP socket, UDP provides no guarantee that the message will ever reach the receiving socket. Furthermore, messages that do arrive to the receiving socket may arrive out of order. Returning to our houses/doors analogy for processes/sockets, UDP is like having a long line of taxis waiting for passengers on the other side of the sender's door. When a passenger (analogous to an application message) exits the house, it hops in one of the taxis. Some of the taxis may break down, so they don't ever deliver the passenger to the receiving door; taxis may also take different routes, so that passengers arrive to the receiving door out of order.
On the other hand, UDP does not include a congestion control mechanism,
so a sending process can pump data into a UDP socket at any rate it pleases.
Although all the data may not make it to the receiving socket, a large
fraction of the data may arrive. Also, because UDP does not use acknowledgments
or retransmissions that can slow down the delivery of useful real-time
data, developers of real-time applications often choose to run their applications
over UDP. Similar to TCP, UDP provides no guarantee on delay. As many of
us know, a taxi can be stuck in a traffic jam for a very long time (while
the meter continues to run!).
| Application | Application-layer protocol | Underlying Transport Protocol |
| electronic mail | SMTP [RFC 2821] | TCP |
| remote terminal access | Telnet [RFC 854] | TCP |
| Web | HTTP [RFC 2616] | TCP |
| file transfer | FTP [RFC 959] | TCP |
| remote file server | NFS [McKusik 1996] | UDP or TCP |
| streaming multimedia | often proprietary (e.g., Real Networks) | UDP or TCP |
| Internet telephony | often proprietary (e.g., Net2phone) | typically UDP |
Figure 2.1-3: Popular Internet applications, their application-layer protocols, and their underlying transport protocols.
Figure 2.1-3 indicates the transport protocols used by some popular Internet applications. We see that email, remote terminal access, the Web and file transfer all use TCP. These applications have chosen TCP primarily because TCP provides the reliable data transfer service, guaranteeing that all data will eventually get to its destination. We also see that Internet telephone typically runs over UDP. Each side of an Internet phone application needs to send data across the network at some minimum rate (see Figure 2.1-2); this is more likely to be possible with UDP than with TCP. Also, Internet phone applications are loss-tolerant, so they do not need the reliable data transfer service (and the acknowledgments and retransmissions that implement the service) provided by TCP.
As noted earlier, neither TCP nor UDP offer timing guarantees. Does this mean that time-sensitive applications can not run in today's Internet? The answer is clearly no - the Internet has been hosting time-sensitive applications for many years. These applications often work pretty well because they have been designed to cope, to the greatest extent possible, with this lack of guarantee. We shall investigate several of these design tricks in Chapter 6. Nevertheless, clever design has its limitations when delay is excessive, as is often the case in the public Internet. In summary, today's Internet can often provide satisfactory service to time-sensitive applications, but it can not provide any timing or bandwidth guarantees. In Chapter 6, we shall also discuss emerging Internet service models that provide new services, including guaranteed delay service for time-sensitive applications.
New public domain and proprietary Internet applications are being developed
everyday. Rather than treating a large number of Internet applications
in an encyclopedic manner, we have chosen to focus on a small number of
important and popular applications. In this chapter we discuss in some
detail four popular applications: the Web, file transfer, electronic mail,
and directory service. We first discuss the Web, not only because the Web
is an enormously popular application, but also because its application-layer
protocol, HTTP, is relatively simple and illustrates many key principles
of network protocols. We then discuss file transfer, as it provides a nice
contrast to HTTP and enables us to highlight some additional principles.
We discuss electronic mail, the Internet's first killer application. We
shall see that modern electronic mail makes use of not one, but of several,
application-layer protocols. The Web, file transfer, and electronic mail
have common service requirements: they all require a reliable transfer
service, none of them have special timing requirements, and they all welcome
an elastic bandwidth offering. The services provided by TCP are largely
sufficient for these three applications. The fourth application, Domain
Name System (DNS), provides a directory service for the Internet. Most
users do not interact with DNS directly; instead, users invoke DNS indirectly
through other applications (including the Web, file transfer, and electronic
mail). DNS illustrates nicely how a distributed database can be implemented
in the Internet. None of the four applications discussed in this chapter
are particularly time sensitive; we will defer our discussion of such time-sensitive
applications until Chapter 6.
[Cisco 1999] Cisco Systems Inc., "ATM
Signaling and Addressing," July 1999.
[Gauthier 1999] L. Gauthier, C.
Diot, J. Kurose, "End-to-end Transmission Control Mechanisms for Multiparty
Interactive Applications on the Internet," Proc. IEEE Infocom 99,
April 1999.
[Fritz 1997] J. Fritz, "Demystifying
ATM Addressing ," Byte Magazine, December 1997.
[ITU 1997] International Telecommunications
Union, "Recommendation
E.164/I.331 - The international public telecommunication numbering
plan," May 1997.
[McKusik 1996] Marshall Kirk McKusick,
Keith Bostic, Michael Karels, and John Quarterman, "The Design and Implementation
of the 4.4BSD Operating System, " Addison-Wesley Publishing Company, Inc.
(0-201-54979-4), 1996. Chapter 9 of this text, is entitled 'The Network
File System' and is on-line at http://www.netapp.com/technology/level3/nfsbook.html.
[Ramjee 1994] R. Ramjee, J. Kurose,
D. Towsley, H. Schulzrinne, "Adaptive
Playout Mechanisms for Packetized Audio Applications in Wide-Area Networks",
Proc.
IEEE Infocom 94.
[RFC 821] J.B. Postel, "Simple Mail
Transfer Protocol," RFC
821, August 1982.
[RFC 854] J. Postel, J, Reynolds, "TELNET
Protocol Specification," RFC
854. May 1993.
[RFC 959] J. Postel, J.
Reynolds, "File Transfer Protocol (FTP),"
RFC 959, Oct. 1985
[RFC 1035] P. Mockapetris, "Domain
Names - Implementation and Specification", RFC
1035, Nov. 1987.
[RFC 1700] J. Reynolds, J. Postel,
"Assigned Numbers," RFC
1700, Oct. 1994.
[RFC 2068] R. Fielding, J. Gettys,
J. Mogul, H. Frystyk, and T. Berners-Lee, "Hypertext Transfer Protocol
-- HTTP/1.1," RFC
2068, January 1997