##Chapter 12 - The Semantic Web
###Introduction
The web is generally setup for human use. We put a URL in the web browser address box, view the page, and then click on links to go elsewhere on the web. This very successful model for a distributed system has been modified to better include computer program to program interaction with the XML web services that we have studied in this book.
One program can call a service from another program on the web and use the returned data in its own processing with no human intervention.
Since XML web services define the interfaces so that any program can interact with any other program, we might say that it defines the syntax or structure of that general relationship. A human is still completely responsible for selecting the relationship. What about the semantics?
The semantics would be information about how entities are related by specific relationships. The semantic web is collection of technologies to represent and allow use of these semantic relations. This can allow computer programs to do some of the selecting based on explicit semantics.
There are two approaches to creating semantic relationships. One is to use natural language processing (NLP) and other artificial intelligence (AI) methods to understand and represent human artifacts. For example, a computer program would read a document and be able to understand the content just from the human language. It is an effort to make programs operate on human artifacts on the web. These artifacts would include the web entities of pages, data, and applications. There is a long history and ongoing efforts in this area, but it has in general proven to brittle for wide-spread adoption on the web. The other approach is to explicitly include semantic information in web entities according to standard models that computer programs can easily process. The semantic web is this second approach and we will cover its major technologies in this chapter.
The semantic web was first proposed by Tim Berners-Lee, Jim Hendler,
and Ora Lassila in a Scientific American article in 2001. The main idea was that all the data on the web should be available to both humans and computer programs. That article uses the common terminology of a software agent for a computer program in order to emphasize that these particular computer programs are purposeful in that they act for a human user or another computer program. A quotation from that article describes this interaction.
"The real power of the Semantic Web will be realized when people create many programs that collect Web content from diverse sources, process the information and exchange the results with other programs. The effectiveness of such software agents will increase exponentially as more machine-readable Web content and automated services (including other agents) become available. The Semantic Web promotes this synergy:
even agents that were not expressly designed to work together can transfer data among themselves when the data come with semantics. [...]
For instance, what today is called home automation requires careful configuration for appliances to work together. Semantic descriptions of device capabilities and functionality will let us achieve such automation with minimal human intervention. A trivial example occurs when Pete answers his phone and the stereo sound is turned down. Instead of having to program each specific appliance, he could program such a function once and for all to cover every local device that advertises having a volume control - the TV, the DVD player and even the media players on the laptop that he brought home from work this one evening."
(Scientific American May 2001)
We will briefly cover the following technologies that form the basis of the semantic web:
- Resource description framework (RDF)
- RDF Schema (RDFS)
- Web Ontology Language (OWL)
- RDF Stores and SPARQL
- RDF
RDF is a W3C standard for metadata for the semantic web. means 'data about data' and how RDF represents this will become clear from the examples below. We will use concepts from the w3schools on- line tutorial on RDF and the W3C RDF Primer in this section (see the syllabus links).
RDF is a graph model that is independent of any serialization. It is an abstract model for relationships between resources. It can be serialized in various ways and one of the most important is XML. So our study of XML will come in handy. RDF models define nodes, arcs, and statements.
Nodes are resources and arcs are relationships. Nodes and arcs must be uniquely identified in some way. The web infrastructure provides the URI mechanism for unique identification.
A statement is a triple of two nodes connected by an arc. This is the basic building block for RDF. The three parts of this triple are called the resource (or subject), the property (or predicate), and the value (or object). So a sample statement in RDF is:
- http://zaad.umbc.edu/class/kippage/ (subject - resource)
- has creator (predicate - property relationship)
- Kip Canfield (object - resource)
An english rendition of this triple is: kippage was created by Kip Canfield. The webpage has a URL, but we need URIs for the predicate and object. We will later see that standard vocabularies using URIs for identifiers are available or we can make up our own, just as we did for namespaces earlier in the book. The triple can be restated as:
- http://zaad.umbc.edu/class/kippage/
- http://purl.org/dc/elements/1.1/creator
- http://userpages.umbc.edu/~canfield/foaf.rdf
Each of these new URLs is an example of a standard vocabulary, but for now we can just view them as identifiers in URI format. This RDF statement can be viewed as a graph as in figure 12.1.
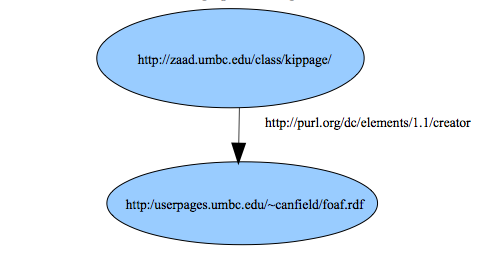
Figure 12.1. An RDF graph.
The triples can be connected together to form a graph of any complexity.
Any nodes that match, can be connected. For example, I have a name that can be represented in a triple:
- http://userpages.umbc.edu/\~canfield/foaf.rdf
- http://xmlns.com/foaf/0.1/name
- "kip Canfield"
Since the node for my identifier matches the previous triple, we can merge them as in figure 12.2.
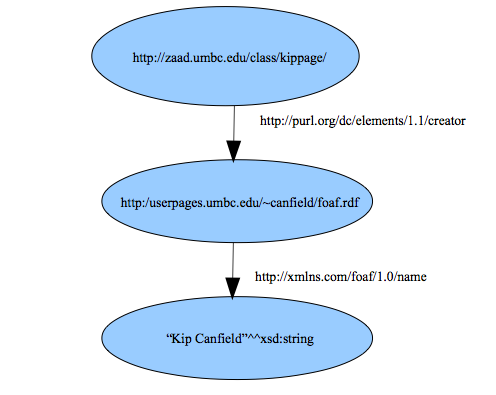
Figure 12.2. An RDF graph.
The name is a string literal and so does not have a URI. It has a datatype and that is usually defined from XMLSchema which uses the double circumflex notation "Kip Canfield"^^xsd:string. Any number of nodes can be so connected to form large graphs. An RDF statement is similar to a record in a database. It is also similar to an assertion in formal logic and can be manipulated as such as we will see later.
There is a nuance to this process of connecting nodes to create graphs.
Since each node has to have a URI, it can result in a proliferation of useless URIs. For example, a person can have an address. An address is made up of standard parts such as street, city, state, and zip. We never want to refer to the address as specific thing that needs a URL, we only want to refer to the parts that make up the address. The RDF specification allows blank nodes (also called a bnodes or anonymous nodes) for this that are prefixed with an underscore. In this way, we do not need to come up with a node identifier for an abstract concept of a specific address, but use a bnode as a placeholder node that aggregates the parts as below:
- http://userpages.umbc.edu/\~canfield/foaf.rdf (subject)
- http://www.w3.org/2006/vcard/ns#Address (predicate)
- _bnode (blank node)
- http://www.w3.org/2006/vcard/ns#street-address (object)
- http://www.w3.org/2006/vcard/ns#locality (object)
- http://www.w3.org/2006/vcard/ns#postal-code (object)
We can serialize this general abstract model in various ways and two popular ones are N3 and XML. N3 is also called Turtle and is a simpler,
more readable syntax, especially good when humans are dealing with the RDF. For example, the second triple in figure 12.2 serialized as N3 would be:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema> .
<http:/userpages.umbc.edu/~canfield/foaf.rdf>
foaf:name
"Kip Canfield"^^xsd:string .
The nodes are URIs with brackets, but can be prefixed (with definitions above) much like namespaces. The three parts of the triple are separated with a space (or return) and the statement ends with a period. The double circumflex notation is used in N3 for datatypes. XML is an alternative serialization and the normative syntax that is used on the web. The same triple would be:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<rdf:Description
rdf:about="http:/userpages.umbc.edu/~canfield/foaf.rdf">
<foaf:name>Kip Canfield</foaf:name>
</rdf:Description>
</rdf:RDF>
where a name is already defined as a string in foaf. This syntax should be understandable from our previous discussion of XML. Both triples from figure 12.2 with an added triple for the web page in XML format would be:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://zaad.umbc.edu/class/kippage/">
<dc:format >text/html</ dc:format >
<dc:creator
rdf:resource="http:/userpages.umbc.edu/~canfield/foaf.rdf"/>
</rdf:Description>
<rdf:Description
rdf:about="http:/userpages.umbc.edu/~canfield/foaf.rdf">
<foaf:name >Kip Canfield</foaf:name >
</rdf:Description>
</rdf:RDF>
We saw some standard vocabularies in RDF in the examples in this chapter. Although one can make up vocabularies to meet special purposes,
it is always better to use a standard one if available and widely used.
The Dublin Core as expressed in RDF/XML is a very common metadata vocabulary for published resources. It was created in 1995 in a library science workshop in Dublin, Ohio using a DTD. There are 15 properties defined such as title and creator. See the w3schools RDF/RDFDublin Core tutorial for the list of the 15 properties and an example.
###RDF Schema
RDFS builds on RDF to add the ability to represent an ontology. An ontology is a formal representation of knowledge as a set of concepts within a domain, and the relationships between those concepts. RDFS does this by adding the concept of class and sub-class (with associated properties) to RDF triples. This is the same kind of concept you are familiar with from object-oriented class hierarchies. For example,
contrary to popular opinion, "kip Canfield" is a type of person. A property of a person is that they can have a child. So RDFS gives us the ability to capture this relationship. Listing 12.1 shows a simple ontology and its representation in RDF with RDFS (N3 notation).
@prefix : <http://www.example.org/sample.rdfs#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
:Animal rdf:type rdfs:Class.
:Dog rdf:type rdfs:Class.
:Person rdf:type rdfs:Class.
:hasChild rdf:type rdf:Property.
:hasDaughter rdf:type rdf:Property.
:hasPet a rdf:Property.
:Cat rdfs:subClassOf :Animal.
:Person rdfs:subClassOf :Animal.
:hasPet rdfs:range :Cat; rdfs:domain :Person.
:hasChild rdfs:range :Animal; rdfs:domain :Animal.
:hasDaughter rdfs:subPropertyOf :hasChild.
:Max a :Cat.
:Kelly a :Person.
:Casey a :Person.
:Kip a :Person;
:hasDaughter :Kelly;
:hasDaughter :Casey.
Listing 12.1. An ontology in RDFS.
Note the following about listing 12.1:
1. We see some details about N3 syntax that we have not seen. The default prefix is defined so that we know :dog is in that default. Multiple triples can be put into a single line using the semicolon and ended as usual by the period.
2. We see the new rdfs: prefixed elements of subClassOf, subPropertyOf, domain, and range. SubClassOf and subPropertyOf do what you would expect - define sub-classes. Domain and range define which classes are valid for properties. The range defines the classes for the values a property can have. The domain defines which classes the property is for. In N3 the string a is shorthand for rdf:type (the use is interchangeable). This makes N3 very readable as for example, :Max a :Cat . = Max is a Cat = :Max rdf:type :Cat .
3. So the classes are Animal, Cat, and Person and the properties are hasChild and hasDaughter. A Person is a sub-class of an Animal and hasDaughter is a sub-property of hasChild. The property hasChild has a range of Animal which means that only Animals can be values for this property. The domain for hasChild is also Animal which means that only Animals can have this property.
An RDF triple like :Kelly :hasPet :Max allows us to make the following inferences (as in formal logic) using RDFS:
- Kelly is an Animal.
- A Cat is an Animal.
- The property :hasPet can only be applied to Persons.
One can translate N3 to XML (or vice versa) using a converter. An example can be found at http://www.rdfabout.com/demo/validator/. So RDFS is a layer on top of RDF that allows us to build ontologies.
The FOAF vocabulary describes persons, their activities and their relations to other people and objects. Anyone can use FOAF to describe him or herself. FOAF allows groups of people to describe social networks without the need for a centralized database. FOAF uses RDFS (and OWL) to create an ontology for persons. If you follow the URL that I used to identify myself in figure 12.2, you will see an example use. These files can be harvested just like Google indexes web pages and aggregated to display social networks. You can follow the URL from the standard namespace http://xmlns.com/foaf/0.1/ to see the specification.
Another vocabulary is the vCard ontology at http://www.w3.org/2006/vcard/ns which was created from an older plain text file format specification of business card or address book information. See http://www.w3.org/Submission/vcard-rdf/.
###OWL
OWL is beyond the scope of our discussion, but it is important to know what it does. OWL adds more vocabulary to describe properties and classes than RDF or RDF Schema. For example, it can describe relations between classes (such as disjointness), restrictions, cardinality (for example, "exactly one"), equality, richer typing of properties, and characteristics of properties (such as symmetry). It is a complex standard and can be difficult to implement.
As an example of how it can be useful, consider listing 12.1. The RDFS tells us that the range for hasPet is Animal. This is fine, but there is small problem. Since Persons are Animals, can I have a Person for a pet?
In OWL, I could make a restriction that excluded Persons from the range.
OWL adds much more powerful logical and ontology tools to RDFS. There is also a rule information format (RIF) that adds rules to OWL, but that is also beyond the scope of our treatment.
###RDF Stores and SPARQL
RDF applications for the semantic web have a similar architecture to the ones that we been discussing but with some differences. Figure 12.3 shows the architecture for semantic web applications.

Figure 12.3. RDF application architecture.
The RDF Store is special kind of database that can parse all RDF data and merge it into a single, federated (combined) graph for query. A query interface allows applications to get data out of the database. We will discuss a query language called SPARQL below. Inferencing uses logic to infer triples from the asserted triples that will also be available for query. For example, Kelly is an Animal is asserted nowhere in the listing 12.1 code, but can be logically inferred by the inference engine and added to the database.
SPARQL is a query language for RDF in an RDF Store and called a SPARQL endpoint. It is another one of those recursive acronyms that stands for itself as SPARQL protocol and RDF query language. Listing 12.2 shows an example of SPARQL.
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name ?email
WHERE {
?person a foaf:Person.
?person foaf:name ?name.
?person foaf:mbox
?email.
}
Listing 12.2. SPARQL.
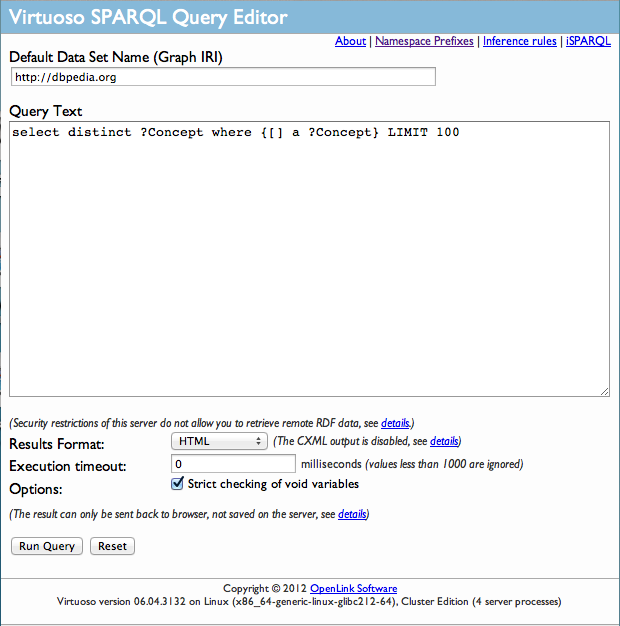
Figure 12.4. SPARQL Endpoint.
It resembles SQL in function and overall syntax with the statements using an N3 syntax. The variables prefixed with the question mark (like ?person) are bound to matches in the RDF Store by the query engine.
The best way to understand the way it works is to try some examples. We can go to a public endpoint that can import RDF data and then query it with SPARQL - there are [many such endpoints](http://www.w3.org/wiki/SparqlEndpoints). Some endpoints are pegged to the source such as the ones at dbpedia. Some are open to remote sources such as http://demo.openlinksw.com/sparql/.
< ?xml version="1.0" encoding="utf-8"?>
< ?xml-stylesheet type="text/xsl" href="/xml-to-html.xsl"?>
<sparql xmlns="http://www.w3.org/2005/sparql-results#">
<head>
<variable name="name"/>
<variable name="email"/>
</head>
<results>
<result>
<binding name="name">
<literal>Aaron Swartz</literal>
</binding>
<binding name="email">
<uri>mailto:me@aaronsw.com</uri>
</binding>
</result>
<result>
<binding name="name">
<literal>Eric Miller</literal>
</binding>
<binding name="email">
<uri>mailto:em@w3.org</uri>
</binding>
</result>
...
</results>
</sparql>
Listing 12.3. SPARQL endpoint return in XML format.
Figure 12.4 show the interface for an enpoint. We enter the following:
- A URL for a file with RDF data. I used the URL for Tim Berners-Lee's FOAF file: http://dig.csail.mit.edu/2008/webdav/timbl/foaf.rdf in the GRAPH IRI box.
- A choice for output. The default will apply an XSLT stylesheet to the RDF return to produce an HTML table. If the output is unspecified, raw XML is returned. One can also choose the other formats listed.
- A SPARQL query such as the one shown in listing 12.2 place in the Query Text box.
The endpoint will bind the variables and display the output. The XML output for the query in listing 12.2 is given in listing 12.3. You can run the query yourself to see the HTML display.
Note that in listing 12.3 a client-side XSLT created the HTML table display. SPARQL queries can include a FILTER that restricts the output.
It is added at the end and contains a restriction on a variable. For example, the query in listing 12.2 could be modified as:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name ?email
WHERE {
?person a foaf:Person.
?person foaf:name ?name.
?person foaf:mbox ?email.
FILTER regex(?name, "^a", "i")
}
This uses a regular expression to get only those names that begin with an A (the "^" is the beginning of a string and the "i" means it is case insensitive). Try this on Tim Berners-Lee's foaf file and see that only 2 names are returned. You should try this query in ARQ. Regular expressions are beyond the scope of our discussion, but note that if there had been a ?age variable available, we could have filtered age with FILTER (?name >50), using a familiar comparison operator. One of the end of chapter exercises will have you use this kind of filter.
There are four types of SPARQL queries:
- SELECT
- CONSTRUCT
- ASK
- DESCRIBE
SELECT is what we see in listing 12.2 and is the by far the most common.
You can try all the following examples in ARQ to see how they work.
CONSTRUCT returns RDF triples rather than XML. For the query:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT {?person foaf:name ?name.}
WHERE {
?person a foaf:Person.
?person foaf:name ?name.
?person foaf:mbox ?email.
}
the following relevant RDF would be returned.
<http://dig.csail.mit.edu/2008/webdav/timbl/foaf.rdf#dj>
<http://xmlns.com/foaf/0.1/name> "Dean Jackson" .
<http://www.aaronsw.com/about.xrdf#aaronsw>
<http://xmlns.com/foaf/0.1/name> "Aaron Swartz" .
<http://dig.csail.mit.edu/2008/webdav/timbl/foaf.rdf#edd>
<http://xmlns.com/foaf/0.1/name> "Edd Dumbill" .
...
ASK just returns a boolean that specifies if the query pattern matches anything in the database. DESCRIBE returns an RDF graph describing the resources that matched. A query of:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
DESCRIBE ?person
WHERE {
?person a foaf:Person.
?person foaf:name ?name.
?person foaf:mbox ?email.
}
returns a description using RDF triples:
...
<http://www.aaronsw.com/about.xrdf#aaronsw>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person> .
<http://www.aaronsw.com/about.xrdf#aaronsw>
<http://www.w3.org/2000/01/rdf-schema#seeAlso>
<http://www.aaronsw.com/about.xrdf> .
<http://www.aaronsw.com/about.xrdf#aaronsw>
<http://xmlns.com/foaf/0.1/mbox>
<mailto:me@aaronsw.com> .
<http://www.aaronsw.com/about.xrdf#aaronsw>
<http://xmlns.com/foaf/0.1/name>
"Aaron Swartz" .
...
where ontology information is used for the description.
The protocols and specifications for the semantic web are commonly shown as a layer cake as in figure 12.5. We have covered most of the layers in figure 12.5. The top layers of proof and trust are beyond the scope of this discussion and are pretty vague in any case. Proof refers to logical proofs for correctness that could be used on RDF data using ontologies. Trust refers to keeping track of a chain of data providers for security and the Crypto in the figure is just encryption services.
Some additional interesting topics related to the semantic web are RDFa and the linked data initiative. RDFa stands for RDF in attributes and is an extension to XHTML attributes that allow one to embed the information for RDF triples in regular web pages. This allows the machine readable information to coexist with the human readable web pages and therefore reduces duplication of effort. A parser can read the XHTML page and construct an RDF file for import to an RDF Store.
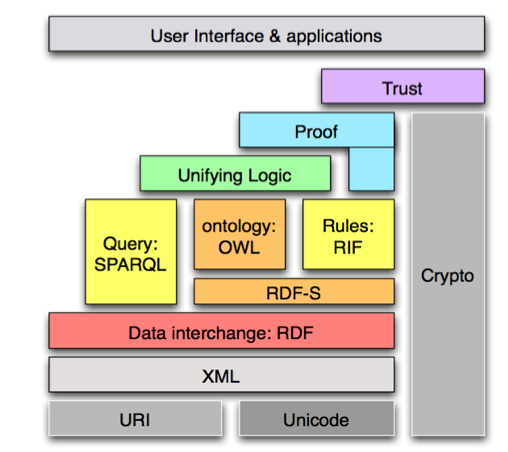
Figure 12.5. The semantic web layer cake.
The linked data initiative tries to unify standards for both the human readable and the computer readable web to make them better integrate and interoperate. It was started by Tim Berners-Lee in 2006 with the short note published at: http://www.w3.org/DesignIssues/LinkedData. You should read this note and see that it integrates the ideas that we have discussed in this book.
###Chapter 12 Exercises
Do the end-of-chapter exercises for each chapter of the book by following the link in the on-line syllabus.