A programmer usually has a choice of data structures and algorithms to use. Choosing the best one for a particular job involves, among other factors, two important measures:
A programmer will sometimes seek a tradeoff between space and time complexity. For example, a programmer might choose a data structure that requires a lot of storage in order to reduce the computation time. There is an element of art in making such tradeoffs, but the programmer must make the choice from an informed point of view. The programmer must have some verifiable basis on which to make the selection of a data structure or algorithm. Complexity analysis provides such a basis.
Complexity refers to the rate at which the storage or time grows as a function of the problem size. The absolute growth depends on the machine used to execute the program, the compiler used to construct the program, and many other factors. We would like to have a way of describing the inherent complexity of a program (or piece of a program), independent of machine/compiler considerations. This means that we must not try to describe the absolute time or storage needed. We must instead concentrate on a "proportionality" approach, expressing the complexity in terms of its relationship to some known function. This type of analysis is known as asymptotic analysis.
Asymptotic analysis is based on the idea that as the problem size grows, the complexity can be described as a simple proportionality to some known function. This idea is incorporated in the "Big Oh" notation for asymptotic performance.
Definition: T(n) = O(f(n)) if and only if there are constants c0 and n0 such that T(n) <= c0 f(n) for all n >= n0.The expression "T(n) = O(f(n))" is read as "T of n is in Big Oh of f of n." Big Oh is sometimes said to describe an "upper-bound" on the complexity. Other forms of asymptotic analysis ("Big Omega", "Little Oh", "Theta") are similar in spirit to Big Oh, but will not be discussed in this handout.
If a function T(n) = O(f(n)), then eventually the value cf(n) will exceed the value of T(n) for some constant c. "Eventually" means "after n exceeds some value." Does this really mean anything useful? We might say (correctly) that n2 + 2n = O(n25), but we don't get a lot of information from that; n25 is simply too big. When we use Big Oh analysis, we usually choose the function f(n) to be as small as possible and still satisfy the definition of Big Oh. Thus, it is more meaningful to say that n2 + 2n = O(n2); this tells us something about the growth pattern of the function n2 + 2n, namely that the n2 term will dominate the growth as n increases. The following functions are often encountered in computer science Big Oh analysis:
A[i] takes the same time independent of the size of the array
A.
The growth patterns above have been listed in order of increasing "size." That is,
O(1), O(lg(n)), O(n lg(n)), O(n2), O(n3), ... , O(2n).
Note that it is not true that if f(n) = O(g(n)) then g(n) = O(f(n)). The "=" sign does not mean equality in the usual algebraic sense --- that's why some people say "f(n) is in Big Oh of g(n)" and we never say "f(n) equals Big Oh of g(n)."
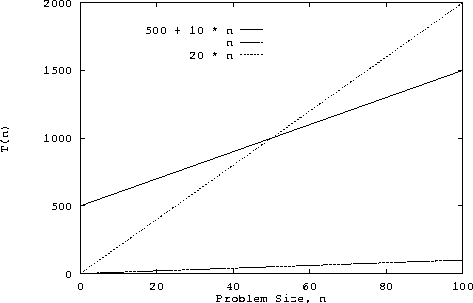
Suppose we have a program that takes some constant amount of time to set up, then grows linearly with the problem size n. The constant time might be used to prompt the user for a filename and open the file. Neither of these operations are dependent on the amount of data in the file. After these setup operations, we read the data from the file and do something with it (say print it). The amount of time required to read the file is certainly proportional to the amount of data in the file. We let n be the amount of data. This program has time complexity of O(n). To see this, let's assume that the setup time is really long, say 500 time units. Let's also assume that the time taken to read the data is 10n, 10 time units for each data point read. The following graph shows the function 500 + 10n plotted against n, the problem size. Also shown are the functions n and 20 n.
Note that the function n will never be larger than the function 500 + 10 n, no matter how large n gets. However, there are constants c0 and n0 such that 500 + 10n <= c0 n when n >= n0. One choice for these constants is c0 = 20 and n0 = 50. Therefore, 500 + 10n = O(n). There are, of course, other choices for c0 and n0. For example, any value of c0 > 10 will work for n0 = 50.
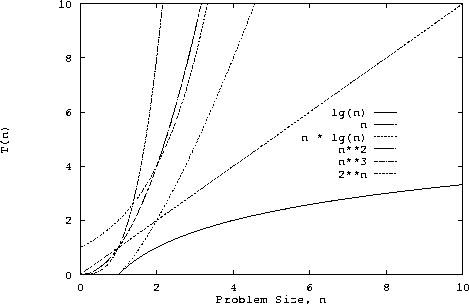
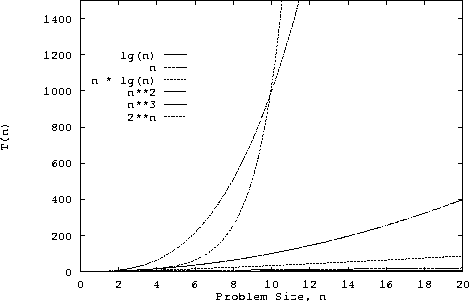
Here we look at the functions lg(n), n, n lg(n), n2, n3 and 2n to get some idea of their relative "size." In the first graph, it looks like n2 and n3 are larger than 2n. They are not! The second graph shows the same data on an expanded scale. Clearly 2n > n2 when n > 4 and 2n > n3 when n > 10.
The following table shows how long it would take to perform T(n) steps on a computer that does 1 billion steps/second. Note that a microsecond is a millionth of a second and a millisecond is a thousandth of a second.
| n | T(n) = n | T(n) = n lg(n) | T(n) = n2 | T(n) = n3 | T(n) = 2n |
|---|---|---|---|---|---|
| 5 | 0.005 microsec | 0.01 microsec | 0.03 microsec | 0.13 microsec | 0.03 microsec |
| 10 | 0.1 microsec | 0.03 microsec | 0.1 microsec | 1 microsec | 1 microsec |
| 20 | 0.02 microsec | 0.09 microsec | 0.4 microsec | 8 microsec | 1 millisec |
| 50 | 0.05 microsec | 0.28 microsec | 2.5 microsec | 125 microsec | 13 days |
| 100 | 0.1 microsec | 0.66 microsec | 10 microsec | 1 millisec | 4 x 1013 years |
Notice that when n >= 50, the computation time for T(n) = 2n has started to become too large to be practical. This is most certainly true when n >= 100. Even if we were to increase the speed of the machine a million-fold, 2n for n = 100 would be 40,000,000 years, a bit longer than you might want to wait for an answer.
Suppose you have a choice of two approaches to writing a program. Both
approaches have the same asymptotic performance (for example, both are O(n
lg(n)). Why select one over the other, they're both the same, right? They
may not be the same. There is this small matter of the constant of
proportionality. Suppose algorithms A and B have
the same asymptotic performance, TA(n) = TB(n) =
O(g(n)). Now suppose that A does ten operations for
each data item, but algorithm B only does three. It is
reasonable to expect B to be faster than A even
though both have the same asymptotic performance. The reason is that
asymptotic analysis ignores constants of proportionality. As a specific
example, let's say that algorithm A is
B is
Algorithm A sets up faster than B, but does more
operations on the data. The execution time of A and
B will be
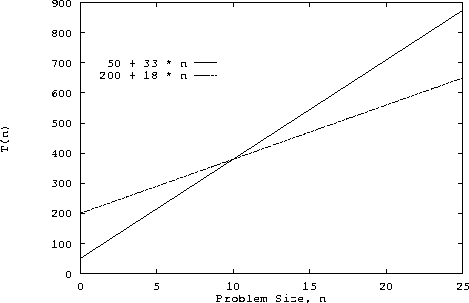
TA(n) = 50 + 3*n + (10 + 5 + 15)*n = 50 + 33*nand
TB(n) =200 + 3*n + (10 + 5)*n = 200 + 18*nrespectively. The following graph shows the execution time for the two algorithms as a function of n. Algorithm
A is the
better choice for small values of n. For values of n >
10, algorithm B is the better choice. Remember that both
algorithms have time complexity O(n).
Modified by Richard Chang, Fri Feb 13 14:25:48 EST 1998.